CPUs clássicas
1. O 8086
O Intel 8086, lançado em 1978, foi um microprocessador de 16 bits que revolucionou a indústria da computação. Ele possuía um barramento de endereços de 20 bits, permitindo acessar até 1 MB de memória. Internamente, a CPU era dividida em duas unidades principais: a Unidade de Interface de Barramento (BIU) e a Unidade de Execução (EU). A BIU era responsável por buscar instruções e dados da memória, enquanto a EU executava as instruções. O 8086 apresentava um conjunto de registradores de 16 bits, incluindo quatro registradores de dados (AX, BX, CX, DX), quatro registradores ponteiro (SP, BP, SI, DI), quatro registradores de segmento (CS, DS, SS, ES) e um registrador de flags. Sua arquitetura de conjunto de instruções complexas (CISC) oferecia uma ampla gama de instruções para manipulação de dados, operações aritméticas e controle de fluxo. O 8086 foi a base para a arquitetura x86. A figura 15.01 exibe um diagrama de arquitetura do 8086.
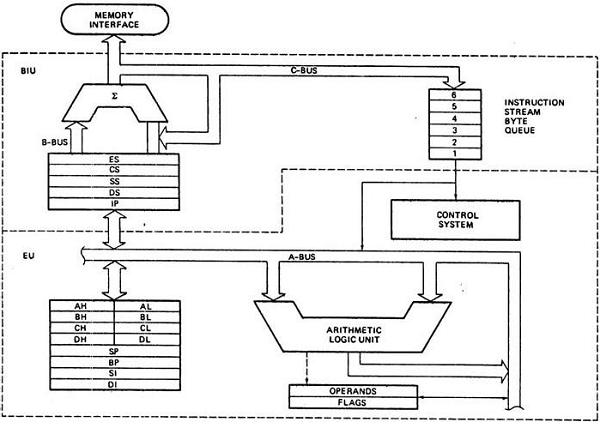
Por que o 8086 é um processador tão influente? A resposta tem a ver com uma empresa que já era gigante no mercado de mainframes e passou a dominar também o mercado de computadores pessoais nos anos 80: a IBM. O primeiro PC da IBM utilizou o 8088, que é uma versão do 8086 com barramento de dados externo de 8 bits. O sucesso do PC da IBM gerou uma enxurrada de clones que, fatalmente, copiaram as decisões de arquitetura do 8086 e acabaram por popularizar o que viria a ser a arquitetura x86.
Não convém falar sobre todas as decisões de arquitetura do x86, mas particularmente duas delas podem informar melhor a maneira como se deu a evolução da arquitetura x86 no futuro:
- A maneira como o 8086 lidava com endereçamento de instruções; e
- A solução de paralelização de fetch de instruções.
1.1. Endereçamento de instruções
Quando falamos de endereçamento de instruções, existem algumas formas que se tornaram extremamente comuns entre os processadores:
Endereçamento imediato
O operando está diretamente contido na instrução.
Ex: LDA 10 (move o valor 10 para o acumulador).

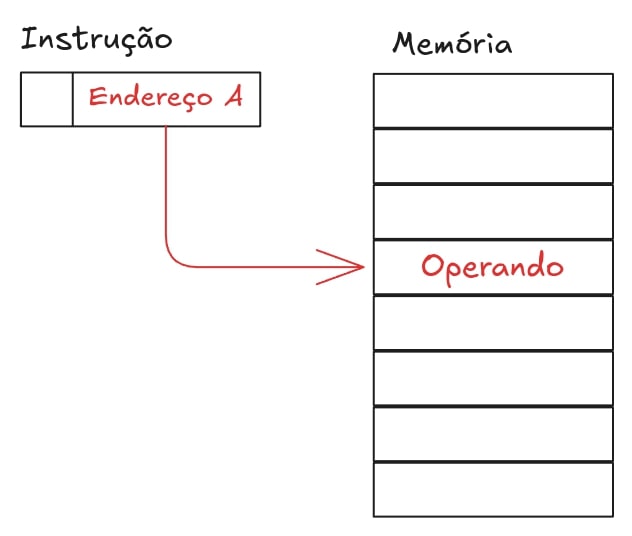
Endereçamento Direto
O endereço do operando é especificado diretamente na instrução.
Ex: LDA A (move o valor armazenado em A para o acumulador).
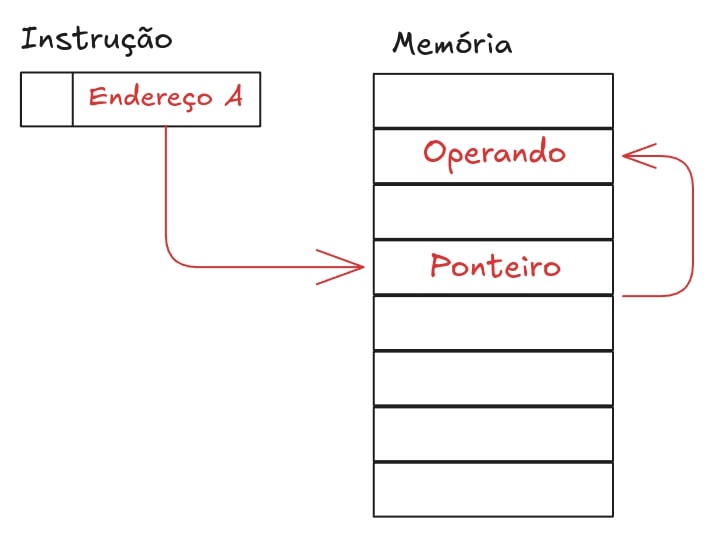
Endereçamento Indireto
A instrução guarda um endereço que aponta para o endereço do operando.
Ex: LDA P (move o valor armazenado no endereço guardado em P para o acumulador).
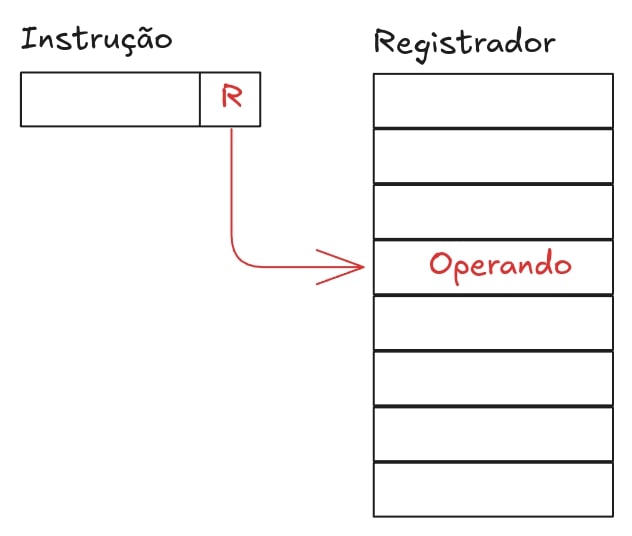
Endereçamento por registrador
O operando está contido em um registrador.
Ex: LDA R (move o valor armazenado no registrador R para o acumulador).
Endereçamento por registrador indireto
O registrador armazena um ponteiro que aponta para o valor do operando.
Ex: LDA PR (move o valor armazenado no endereço apontado por PR para o acumulador).
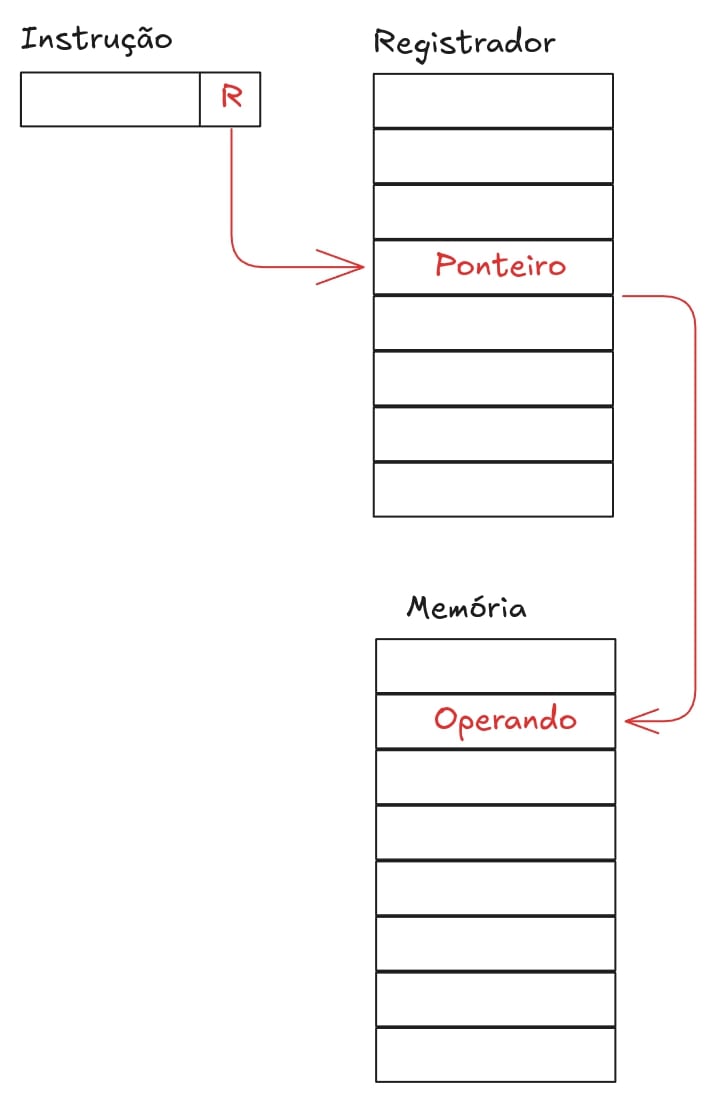
Endereçamento por deslocamento
Há uma operação de soma necessária para obter o endereço do operador.
Ex: LDA R+A (move o valor armazenado no endereço R+A para o acumulador).
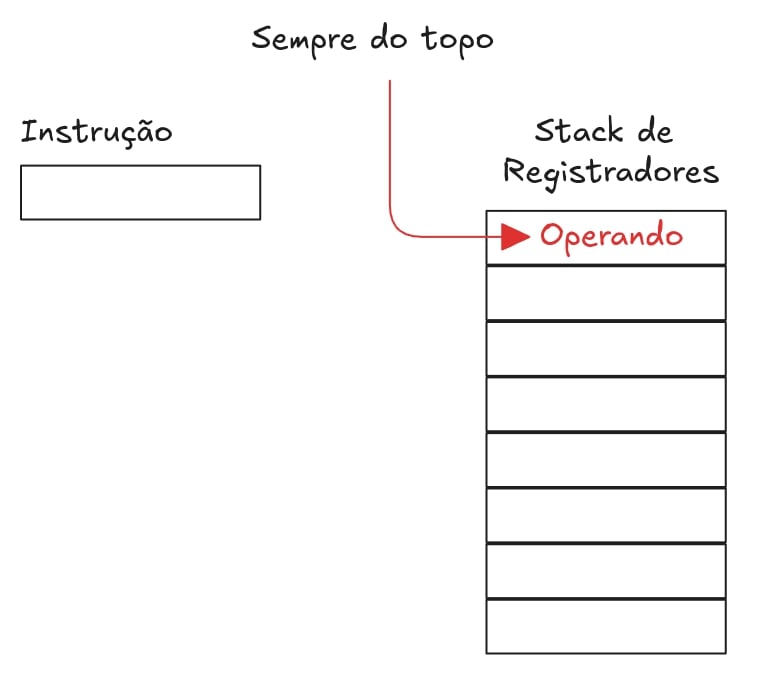
Endereçamento por pilha
O operando está no topo da pilha de registradores.
Ex: LDA S (move o valor armazenado no topo da pilha S para o acumulador).
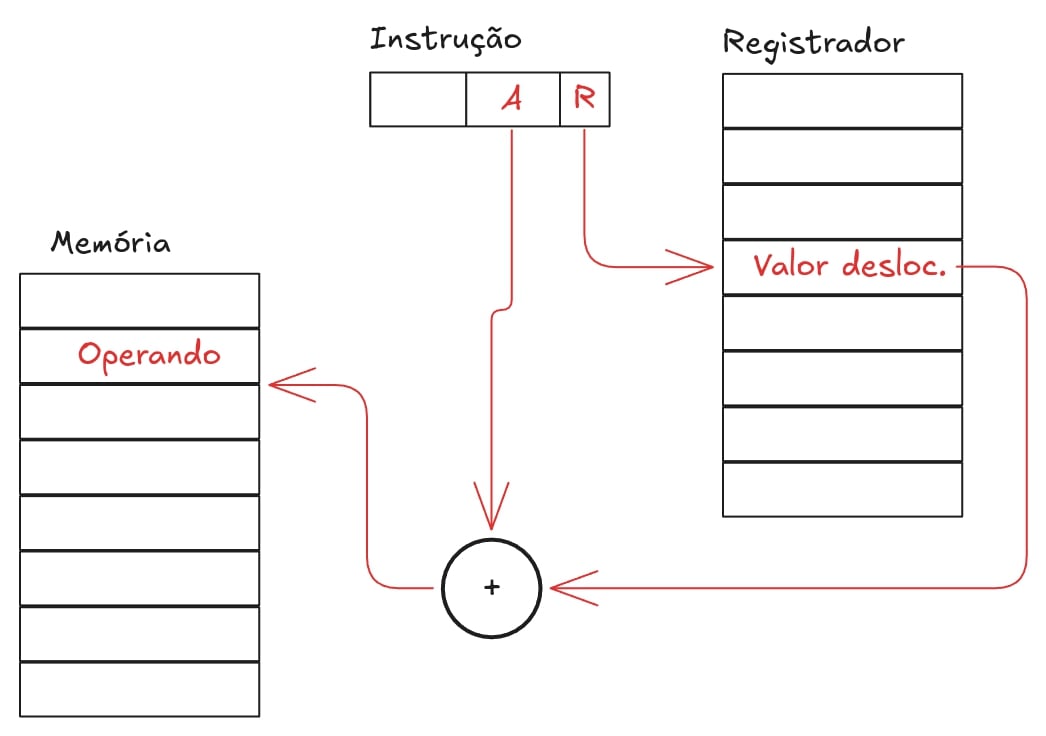
Endereçamento x86
O endereçamento típico da família x86 utiliza o conceito de segmentação. Um endereço lógico é composto por um segmento e um deslocamento. O registrador de segmento contém o endereço base do segmento, e o deslocamento especifica a posição dentro do segmento. O endereço físico é calculado multiplicando o valor do segmento por 16 e adicionando o deslocamento. Isso é feito para que seja possível utilizar endereçamento de 20 bits com barramento de dados de apenas 16bits. O vídeo abaixo explica com mais detalhes o endereçamento da arquitetura x86 para 32 bits.
1.2. Prefetch
O 8086 utilizava um sistema de prefetch de instruções para melhorar o desempenho. A Unidade de Interface de Barramento (BIU) buscava a próxima instrução da memória enquanto a Unidade de Execução (EU) processava a instrução atual. As instruções eram armazenadas em uma fila de prefetch, permitindo que a EU tivesse acesso rápido à próxima instrução. Esse mecanismo de prefetch ajudava a reduzir o tempo de espera por instruções, aumentando a eficiência da CPU. Quando a EU encontrava uma instrução de desvio, a fila de prefetch era descartada e a BIU começava a buscar instruções a partir do novo endereço. O tamanho da fila de prefetch no 8086 era de 6 bytes. Esse sistema simples de prefetch contribuiu para o sucesso do 8086 e influenciou o desenvolvimento de técnicas mais avançadas de prefetch em processadores posteriores.
2. Considerações sobre cache
Cache é uma memória de alta velocidade e menor capacidade que armazena cópias de dados frequentemente acessados da memória principal (RAM). O objetivo principal do cache é reduzir o tempo médio de acesso aos dados, acelerando o desempenho do sistema.
O cache é geralmente dividido em níveis hierárquicos, sendo os mais comuns L1, L2 e L3:
-
L1 (Cache de Nível 1): O cache mais rápido e menor, geralmente integrado ao núcleo do processador. Possui latência muito baixa e é usado para armazenar dados acessados com mais frequência. Pode ser dividido em cache de instruções (L1i) e cache de dados (L1d).
-
L2 (Cache de Nível 2): Maior e mais lento que o L1, geralmente compartilhado entre alguns núcleos do processador. Armazena dados que não estão presentes no L1, mas que são frequentemente acessados.
-
L3 (Cache de Nível 3): O maior e mais lento dos três níveis, geralmente compartilhado por todos os núcleos do processador. Serve como um último nível de cache antes de acessar a memória principal.
A hierarquia da memória do computador é organizada em níveis, com base na velocidade e custo:
- Registradores: Memória interna do processador, extremamente rápida e de capacidade muito limitada.
- Cache (L1, L2, L3): Memória de alta velocidade que armazena cópias de dados da RAM.
- Memória Principal (RAM): Memória volátil que armazena os dados e programas em execução.
- Memória Secundária (Disco Rígido, SSD): Memória não volátil que armazena dados permanentemente.
O cache influencia significativamente o ciclo de fetch (busca de instruções e dados). Quando o processador precisa acessar um dado, ele primeiro verifica o cache L1. Se o dado estiver presente (cache hit), o acesso é rápido. Caso contrário (cache miss), o processador busca o dado no L2, depois no L3 e, por fim, na RAM, em ordem crescente de latência. A presença do dado no cache acelera o processo de busca, evitando o acesso à memória principal, que é mais lento.
A MMU (Memory Management Unit - Unidade de Gerenciamento de Memória) desempenha um papel crucial na utilização do cache. Ela traduz os endereços virtuais usados pelo processador em endereços físicos da memória. A MMU também gerencia a tabela de páginas, que mapeia as páginas da memória virtual para as páginas da memória física. Essa funcionalidade permite que o sistema operacional utilize o cache de forma eficiente, garantindo que os dados corretos sejam armazenados e recuperados.
Existem três formas principais de mapeamento de cache:
-
Mapeamento Direto: Cada bloco da memória principal pode ser mapeado para apenas uma linha específica do cache. É simples de implementar, mas pode levar a conflitos se blocos frequentemente acessados mapearem para a mesma linha.
-
Mapeamento Associativo: Um bloco da memória principal pode ser mapeado para qualquer linha do cache. Oferece maior flexibilidade e reduz conflitos, mas é mais complexo de implementar.
-
Mapeamento Associativo por Conjuntos: Um meio termo entre o mapeamento direto e o associativo. A memória é dividida em conjuntos, e cada bloco pode ser mapeado para qualquer linha dentro do seu conjunto. Oferece um bom equilíbrio entre desempenho e complexidade.
3. O 80486
O Intel 80486, lançado em 1989, representou um grande salto em relação ao seu predecessor, o 80386. Ele foi o primeiro processador x86 a integrar um coprocessador matemático (FPU) e um cache de nível 1 (L1) diretamente no chip, além de implementar um pipeline de instruções mais sofisticado. Essas características contribuíram significativamente para o aumento do desempenho, tornando o 80486 um processador popular em computadores pessoais e servidores da época. A figura 15.09 apresenta o diagrama arquitetural do 80486.
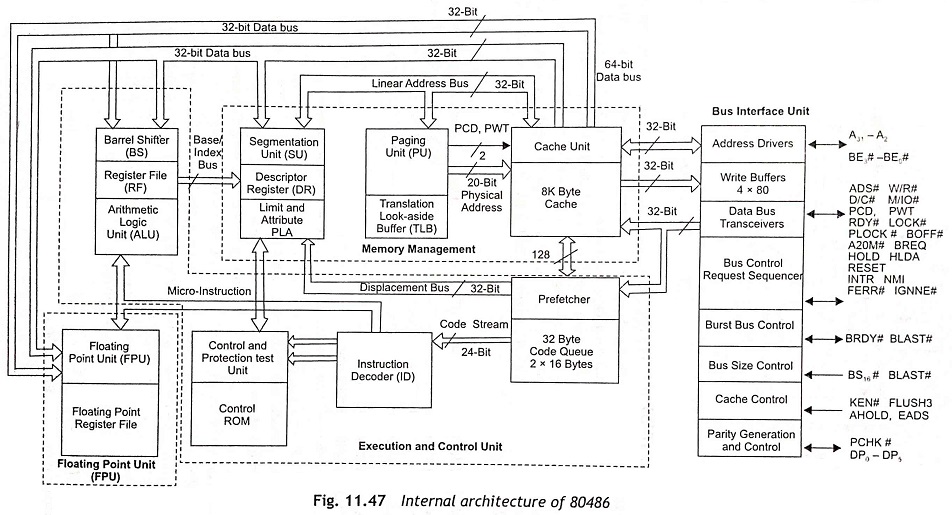
O 80486 implementou um pipeline de cinco estágios, permitindo que múltiplas instruções fossem processadas simultaneamente em diferentes estágios. Isso representou um avanço significativo em relação aos pipelines mais simples utilizados em processadores anteriores. A otimização do pipeline no 80486 demonstrou o potencial dessa técnica para aumentar o desempenho, contribuindo para sua popularização em microprocessadores subsequentes. A partir do 80486, o pipeline se tornou um elemento fundamental na arquitetura de processadores, sendo constantemente aprimorado e expandido em gerações futuras.
3.1. A FPU
A Unidade de Ponto Flutuante (FPU) integrada ao 80486 era um coprocessador matemático dedicado a realizar operações de ponto flutuante, como adição, subtração, multiplicação e divisão de números reais. Antes do 80486, a FPU era um componente separado, o que implicava em custos adicionais e menor desempenho. A integração da FPU ao chip do 80486 acelerou significativamente os cálculos de ponto flutuante, beneficiando aplicações como softwares de CAD, modelagem 3D e jogos.
A FPU do 80486 era compatível com o padrão IEEE 754 para aritmética de ponto flutuante, garantindo precisão e consistência nos cálculos. Ela possuía oito registradores de 80 bits para armazenar valores de ponto flutuante e um conjunto completo de instruções para realizar operações matemáticas complexas.
3.2. Pipeline de Instruções
O pipeline de instruções é uma técnica que divide o processamento de uma instrução em múltiplos estágios, permitindo que várias instruções sejam processadas simultaneamente em diferentes estágios do pipeline. Cada estágio realiza uma parte específica do processamento, como busca da instrução, decodificação, execução e escrita de resultados.
No 80486, o pipeline de cinco estágios consistia em:
- Busca da Instrução (IF): Busca a próxima instrução da memória.
- Decodificação da Instrução (ID): Decodifica a instrução e busca os operandos.
- Execução (EX): Realiza a operação especificada pela instrução.
- Acesso à Memória (MEM): Acessa a memória para ler ou escrever dados, se necessário.
- Escrita de Volta (WB): Escreve o resultado da operação de volta ao registrador ou memória.
Enquanto uma instrução está sendo executada em um estágio, a próxima instrução já pode estar sendo buscada no estágio anterior. Essa sobreposição de execução permite que o processador processe instruções de forma mais eficiente, aumentando o throughput (quantidade de instruções processadas por unidade de tempo).
O pipeline de instruções do 80486 foi um marco na evolução da arquitetura x86, abrindo caminho para pipelines ainda mais complexos e eficientes em processadores subsequentes. Essa técnica se tornou fundamental para o aumento do desempenho dos processadores modernos.