Paradigmas de computação
Na seção antrior estabelecemos que, após a construção do ENIAC, começamos uma era da computação em que os avanços eram exponenciais. Se você fizer um recorte de cada uma das décadas desde os anos 40 até os anos 2020, a computação vai ter uma cara radicalmente diferente em cada uma dessas décadas. Em alguns casos, há mais de uma revolução dentro da mesma década.
Seres humanos adoram esconder conceitos complexos por trás de abstrações. É por isso que temos a tendência a categorizar tudo. É natural que um assunto tão complexo e com uma história tão rica quanto a computação também seja dividido em seções. Onde quero chegar com isso? Quero chegar em uma das maneiras mais comuns de se dividir/seccionar a computação é pensando em diferentes paradigmas.
1. Computação sequencial
Essa seção pode começar e acabar bem rápido com: é o paradigma mais antigo e o que você está acostumado a fazer desde que fez o seu primeiro programa. Uma sequência de passos traduzida em uma série de comandos que são executados sequencialmente e em um núcleo computacional apenas. Por mais que hoje existam paradigmas muito mais complexos, a maioria esmagadora das soluções computacionais vive aqui. E tem um bom motivo: funciona, e funciona bem. Se você não esbarrou em uma das limitações da programação sequencial, in loco e em um único núcleo, então deveria ficar onde está. É fácil, sem confusão e tem bolo.

Eu disse que a seção pode começar e acabar bem rápido, não que vai. Vou aproveitar aqui para contar um pouco mais de história, afinal esse paradigma é tão intuitivo, mas tão intuitivo que ele surgiu antes mesmo do primeiro computador.
Na seção anterior eu mencionei o projeto de Charles Babbage, o motor analítico. O que eu não mencionei é que o projeto de Babbage era tão complexo que foi necessário documentar claramente como operar o equipamento em termos de input e operações possíveis. Efetivamente Charles Babbage criou o primeiro conjunto de microcode da história. Claro, era um microcode puramente mecânico e bastante limitado. Está confuso? Não sabe o que é microcode? Tá na hora de você trabalhar um pouquinho...
Pesquise o que é microcode e qual a diferença do microcode para a microarquitetura e o instruction set de um processador. Considere a afirmação (minha) de que a diferença entre os dois é fundamental para que seja possível programar uma quantidade enorme de dispositivos computacionais de forma homogênea. Por que eu fiz essa afirmação? Apoie-se na diferença entre microarquitetura, instruction set e microcode para fazer sua resposta.
Ok, mas o que isso tem a ver com a computação sequencial? Bom, em 1843, uma colega matemática de Babbage escreveu em suas anotações uma sequência de instruções para o motor analítico para que ele calculasse a série de Bernoulli. Essas instruções hoje são reconhecidas como o primeiro algoritmo da história e sua autora, Ada Byron, a condessa de Lovelace, entrou para a história como a primeira programadora. O vídeo abaixo é um resumo da história dessa figura histórica da computação.
Não há muito o que falar sobre a computação sequencial que já não é algo internalizado por qualquer um que programa há mais do que alguns dias; uma sequência de instruções é coletada, interpretada e executada por uma CPU de forma síncrona. Se você estava ligado em alguma das aulas em que falei de arquitetura de computadores, pode ter percebido que a escolha de palavras aqui traça um paralelo perfeito com fetch, decode, execute. Esse paradigma virou o padrão para aqueles que queriam explorar os novos computadores dos anos 60, que já utilizavam quase exclusivamente o que hoje conhecemos como arquitetura de von neumann.

Junto com essa arquitetura e o paradigma sequencial, surge também a Lei de Moore. A lei de Moore vem de uma observação feita por Gordon Moore em seu artigo de 1965, Cramming more components onto integrated circuits. Moore notou que havia uma tendência em que a densidade de transistores em processadores dobrava a cada 1.5 anos.

A figura que estou pintando aqui é de um mundo novo e em franca expansão; as possibilidades eram quase infindáveis e quase nenhuma havia sido explorada. Havia uma arquitetura nova que fazia com que programar computadores deixasse de ser uma tarefa exclusiva para os matemáticos envolvidos na criação das primeiras máquinas. Havia até uma tendência de aproximadamente dobrar o poder computacional a cada 2 anos, fazendo com que novas possibilidades surgissem mais rápido do que os entusiastas e pesquisadores conseguiam explorá-las. Basicamente, o que houve a partir dos anos 60 foi uma era de ouro da computação.
Todos sabemos como termina a era de ouro, certo?

2. Computação paralela
Não, não estou falando dessa era de ouro graças a Deus.
Quase tão famosa quanto a lei de Moore em si é a frase: A lei de Moore está morta. Essa frase foi dita incontáveis vezes sempre que a evolução do processador esbarrava em alguma dificuldade técnica. A primeira vez que essa frase realmente ganhou tração foi no começo dos anos 2000 (detalhe inútil: eu já estava usando/montando computadores nessa época com meus 10 anos de idade e meus 13 disquetes para instalar o Windows 95 =D).

De fato parecia que finalmente o ritmo frenético de evolução das CPUs iria
frear um pouco. Tudo indicava que o ritmo frenético de evolução dos últimos 40
anos finalmente estava chegando em um plateau. Acabou, vamos todos respirar
agora e tirar o máximo desses dispositivos que agora, finalmente, vão parar de
evoluir tão rápido. Certo? Errado! Se tem uma coisa que a história da ciência
nos ensina é que não sabemos nada sobre a infindável malícia dentro do coração
humano nunca se deve duvidar da nossa capacidade de inovação.
Entra a computação paralela. Em meados dos anos 2000 surgiu a resposta para o problema; se não dá mais para dobrar a densidade de transistores a cada 2 anos, que tal dobrar a quantidade de processadores por chip? E foi assim que surgiram duas CPUs muito importantes para um novo paradigma de computação:
- Intel Pentium Extreme 840 (chip da família de workstations - Xeon - que
depois teve sua contrapartida para o consumidor final, o Pentium
D
isastre); e - Atlhon 64 x2.
Assim como curiosamente acontece hoje, naquela época a AMD ficou muito à frente da Intel por ter utilizado uma estratégia mais inteligente para a criação do seu chip dual core. Basicamente, o Atlhon 64 x2 contava com dois núcleos que tinham acesso a uma memória de alta performance para a comunicação entre os dois núcleos. Essa memória ficava logo após o cache L2. A imagem abaixo exibe de forma simplificada essa escolha de arquitetura da AMD.

Enquanto isso, a Intel contava com um Bus de relativa baixa performance para a comunicação entre dois núcleos totalmente separados. A imagem abaixo exemplifica essa escolha.

Eu deixei bem claro que considero que a AMD tomou a decisão mais acertada, mas você como bom estudante sabe que deve confiar no seu professor, mas verificar o que ele fala. Pesquise diagramas de arquitetura de CPUs mais modernas e compare com as arquiteturas apresentadas nas figuras acima. O que é possível notar em comum, principalmente se focarmos no acesso à memória por cada núcleo? Na sua opinião, os chips modernos tem mais em comum com o Atlhon 64 x2 ou com o Pentium D 840?
Vamos de ciências térmicas? O que significa TDP? Pesquise o termo e responda qual é a diferença entre o TDP e a potência de consumo de um componente eletrônico. Como se calcula TDP?
Por quê entrei nessa tangente para falar do paradigma de computação paralela? Pois acesso compartilhado a memória é O assunto mais importante quando falamos de paralelismo (ou sistemas distribuídos).
2.1. Taxonomia de Flynn
Para esta seção, permitam-me roubar citar um conteúdo diretamente da
Wikipedia:
Taxonomia (do grego antigo τάξις, táxis, "arranjo" e νομία, nomia, "método") é a disciplina biológica que define os grupos de organismos biológicos com base em características comuns e dá nomes a esses grupos. Para cada grupo, é dada uma nota. Os grupos podem ser agregados para formar um supergrupo de maior pontuação, criando uma classificação hierárquica.
A pergunta que deve estar na sua cabeça agora é: quem é Flynn e por que ele tem uma taxonomia. Ou, talvez: o que diabos grupos de organismos biológicos tem a ver com computação. Ou, possivelmente: quem é o mesmo que a plaquinha do elevador fica ameaçando de estar no mesmo andar que eu?
Se você teve alguma dessas dúvidas, relaxa que eu vou te ajudar agora!
Michal J. Flynn é um professor emérito de Stanford que foi membro fundador e primeiro chairman do comitê técnico sobre arquitetura computacional da IEE Computer Society. Em 1966, Flynn propos um método para classificar a computação digital paralela. Esse método ficou conhecido como a Taxonomia de Flynn.
Beleza, mas por quê taxonomia? Pegue a definição de taxonomia e omita os termos "biológica" ou "biológicos". Pronto, tá aí.
E o mesmo? Sei lá, melhor continuar tomando cuidado.
Legal, mas o que diz a Taxonomia de Flynn?
Ela divide os tipos de tarefa de computação digital em quatro tipos:
- Single instruction stream, single data stream (SISD)
- Single instruction stream, multiple data stream (SIMD)
- Multiple instruction stream, single data stream (MISD) e
- Mulitple instruction stream, multiple data stream (MIMD)
Vamos explorar individualmente cada uma delas?
Foi uma pergunta retórica. Vamos.
Single instruction, single data (SISD)

Vendo a imagem acima e a sua descrição já deve deixar claro que o SISD nada mais é do que a denominação da computação sequencial dentro da taxonomia de Flynn. O que vou aproveitar para ressaltar aqui é que essa taxonomia foca em duas coisas:
- Quantos fluxos de entrada de dados o sistema tem?
- Quantas instruções distintas em paralelo o sistema é capaz de executar?
Essas são as duas perguntas essenciais para essa taxonomia.
Considerando a arquitetura SISD disposta acima, cite um exemplo de arquitetura computacional/dispositivo que exemplifica esse tipo de arquitetura.
Single instruction, multiple data (SIMD)

Este é o primeiro exemplo de arquitetura paralela possível. Temos uma única instrução que pode ser aplicada para diversos fluxos de dados heterogêneos. Quando pensamos onde esse tipo de situação pode existir, caímos imediatamente no mundo da álgebra linear com vetores, matrizes e tensores. Tendo isso em vista, vamos para mais um exercício?
Considerando a arquitetura SIMD disposta acima, cite um exemplo de arquitetura computacional/dispositivo que exemplifica esse tipo de arquitetura. Além disso, cite uma aplicação que se beneficia amplamente deste tipo de arquitetura.
Multiple instruction, single data (MISD)

O MISD é um pokémon mais difícil de encontrar em campo. Tesmo apenas uma entrada de dados e mais de uma operação com instruções distintas em unidades computacionais diferentes. Esse tipo de paralelismo obviamente não tem ganho algum de performance. O que isso significa? Que você vai ter que pesquisar agora por que diabos essa arquitetura existe =D
Qual é a razão de existir da arquitetura MISD? Em que tipo de situação ela é vantajosa? Cite exemplos.
Multiple instruction, multiple data (MIMD)

Por fim, chegamos no tipo de paralelismo comum às CPUs (e, portanto, o tipo de paralelismo mais acessível e comum para a maioria dos desenvolvedores). Aqui temos várias unidades computacionais independentes, executando instruções diferentes com dados diferentes. De fato, se pensarmos nos núcleos de uma CPU, é exatamente assim que funciona. Esse tipo de paralelismo é extremamente influenciado pelo tipo de compartilhamento de memória. Mesmo que cada núcleo funcione como uma unidade separada, é muito comum precisar consolidar todos os dados processados para finalizar o programa.
2.2. Considerações sobre memória
Voltando para a comparação entre o Atlhon x2 e o Pentium D, percebemos que o fator que sacramentou a vitória do Atlhon x2 (será? Você já fez o exercício 2.02?) não foi uma frequência maior ou uma quantidade de operações por ciclo maior, mas sim como se dava o compartilhamento de memória entre os núcleos.
Em outras palavras, é possível afirmar que como você usa a memória é um fator que pode viabilizar ou não a computação em paralelo. Preste atenção pois a próxima frase é importante. Vou até colocar em um admonition, olha só quão importante é:
Não existe a menor possibilidade de um sistema de computação paralela ter absolutamente zero overhead. Sendo assim, se aventurar na computação paralela sem uma real necessidade significa jogar performance no lixo.
Vamos falar sobre as principais classificações a respeito do uso de memória na computação paralela? Aqui basicamente temos sistemas de memória compartilhada, sistemas de memória distribuída, sistemas com acesso uniforme à memória e sistemas com acesso não uniforme à memória.
Memória compartilhada vs memória distribuída
Essa dicotomia trata sobre como as diferentes unidades computacionais acessam a memória e podem compartilhar (ou não) as variáveis que dizem respeito ao algoritmo a ser executado. Existem duas possibilidades aqui: ou todas as unidades computacionais acessam o mesmo recurso de memória ou a memória é distribuída, sem que as unidades computacionais consigam acessar os mesmos engereços.

Considerando sistemas com memória compartilhada e sistemas com memória distribuída, cite ao menos um ponto positivo e um ponto negativo para cada um desses tipos de sistema. Considere a capacidade do sistema de ter coerência de dados (se não souber o que isso significa, pesquise o termo) e a possibilidade de conflitos de manipulação de dados (o termo chave aqui é race condition).
Acesso uniforme vs acesso não uniforme
Efetivamente aqui temos o tipo mais comum de sistema de computação paralelo que vamos encontrar por aí na natureza; o sistema com acesso não uniforme à memória. O fato é que sistemas computacionais costumam ter heterogeneidade com relação ao acesso à memória. Isso significa que assim que o problema escalar para um nível em que precisamos de mais de um computador, caímos no sistema com acesso não uniforme. Isso não é exatamente uma boa coisa, pois é muito mais complexo lidar com essa falta de uniformidade. No entanto, o custo atrelado à escalabilidade de um sistema puramente uniforme é proibitivo. Fazemos o melhor com aquilo que temos.

3. Computação distribuída
A computação paralela resolveu bem o problema do "fim da lei de moore", porém uma coisa que aconteceu muito rápido é que o aumento da demanda por recursos computacionais começou a vencer até mesmo a acelerada evolução da capacidade computacional dos processadores. O que fazer quando nem com um programa rodando em paralelo em vários núcleos consegue a performance que você precisa? Seguindo a mesma lógica que nos levou à computação paralela, a resposta é mais computadores.
Ok, agora começou a ficar bem mais complexo. Quando falamos de computação distribuída estamos falando de vários computadores trabalhando em conjunto para resolver o mesmo problema, e isso pode assumir muitas caras. Logo de cara, há uma lista de expectativas para que sequer valha a pena seguir com esse paradigma:
- Transparência: o sistema deve fornecer ao usuário o uso do conjunto de computadores tendo em vista apenas o problema computacional a ser resolvido, de modo que a infraestrutura em si fica "transparente", ou seja, o usuário não precisa se preocupar com isso.
- Confiabilidade: o sistema não pode ter um ponto de falha único que faça todo o sistema sair do ar. Para isso, sistemas de computação distribuída devem ser capazes de detectar e se recuperar de crashes.
- Escalabilidade: o sistema deve ter a flexibilidade para aumentar de forma que o custo não aumente exponencialmente. Sendo assim, a relação entre custo e benefício de utilizar esse tipo de sistema se justifica perando um sistema centralizado.
- Segurança: os recursos (dados) de um sistema de computação distribuída devem ter proteção contra destruição ou acesso não autorizado.
- Performance: esse ponto é um tanto óbvio, mas deve haver um ganho real de performance para justificar utilizar um sistema distribuído em vez de um único computador.
A partir dessas expectativas, surgem alguns paradigmas distintos dentro da computação distribuída:
- Peer-to-peer
- Clusters
- Grid computing
3.1. Peer-to-peer
Quando falamos em peer-to-peer, é praticamente impossível para qualquer pessoa que seja versada na cultura da internet não lembrar imediatamente das tecnologias de torrent. Sistemas de torrent são caracterizados pelo compartilhamento de conteúdo sem que os arquivos estejam localizados em um servidor centralizado. Na verdade, nem mesmo existe o conceito de servidor e cliente. Esses são substituídos por peers e leechers. Os pares (peers) são aqueles dispositivos que já tem o arquivo completo e estão servindo os arquivos para os leechers, ou sanguessugas (essa tradução fica um tanto feia no português =O).
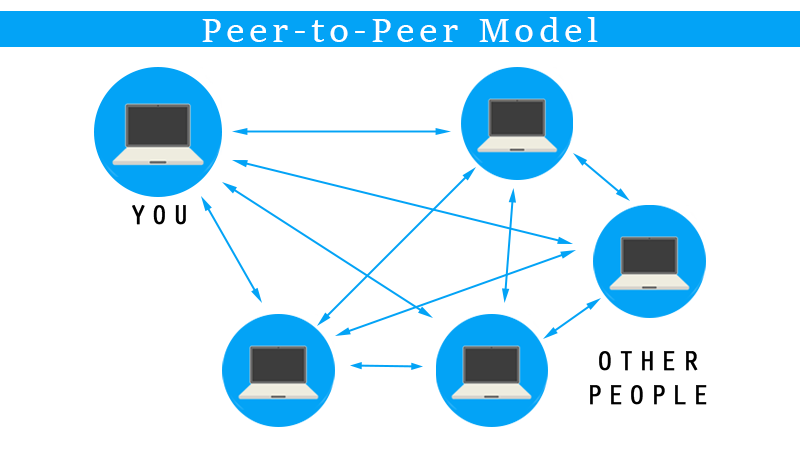
Usando a analogia com o sistema de torrent, podemos concluir que o modelo de computação peer-to-peer (P2P) caracteriza-se pela ausência de um servidor central, com cada nó na rede funcionando simultaneamente como cliente e servidor. Essa arquitetura descentralizada oferece várias vantagens, incluindo a distribuição de carga de trabalho, maior resiliência a falhas e a eliminação de pontos únicos de falha. Em um sistema P2P, cada nó pode compartilhar recursos, como arquivos ou poder de processamento, diretamente com outros nós, facilitando a colaboração e o compartilhamento de informações.
Apesar do torrent ser o exemplo mais clássico possível, há outros sistemas que funcionam utilizando o paradigma peer-to-peer. Pesquise e cite ao menos mais dois exemplos (um dos exemplos possíveis é até mais famoso que torrent hoje em dia).
3.2. Clusters

Clusters são conjuntos de computadores interconectados que trabalham em conjunto para atuar como um único sistema coeso. Cada nó de um cluster possui seus próprios recursos de processamento e memória, e a comunicação entre os nós é realizada através de redes de alta velocidade. Esse modelo é amplamente utilizado em aplicações que requerem grande capacidade de processamento e armazenamento, como simulações científicas, análise de grandes volumes de dados e hospedagem de serviços web.
A configuração de um cluster pode variar significativamente, desde alguns computadores conectados em uma rede local até milhares de nós distribuídos em data centers. Clusters permitem uma escalabilidade significativa, onde o desempenho pode ser melhorado com a adição de mais nós ao sistema. Um exemplo notável é o uso de clusters em supercomputação, onde tarefas extremamente complexas, como simulações climáticas ou sequenciamento genético, são divididas e distribuídas entre vários nós para serem processadas de forma paralela e eficiente.
O paradigma de clusters destaca-se por sua alta disponibilidade e confiabilidade, com redundância embutida para mitigar falhas de hardware. Além disso, a infraestrutura de clusters frequentemente inclui sistemas de gerenciamento de recursos e balanceamento de carga para otimizar o uso dos recursos disponíveis. Isso torna os clusters uma escolha popular para organizações que necessitam de soluções robustas e escaláveis para processamento intensivo de dados.
3.3. Grid computing
Surpresa! Essa seção está intencionalmente vazia. Grid computing é um dos paradigmas que aparece de forma razoavelmente prevalente em nossa sociedade, mas tipicamente acaba sendo um dos paradigmas "esquecidos". Sua tarefa é pesquisar o que é grid computing e dar pelo menos um exemplo de sua aplicação.
4. Computação em nuvem
A ideia de utilizar vários computadores para resolver o mesmo problema já foi um divisor de águas para quem precisava de mais recurso computacional e tinha esbarrado no limite do que era possível com apenas um computador de alta performance, mas nem tudo na computação diz respeito à performance. Com o crescimento desenfreado da internet, começou a ser cada vez mais comum a necessidade de empresas de servir serviços computacionalmente intensos (ou não) para vários continentes ao mesmo tempo. Aqui o problema deixou de ser performance para ser um problema um pouco mais difícil de resolver: a distância entre o servidor e o cliente.
Por que um pouco mais difícil? Pensa comigo: aproximando a terra para uma esfera perfeita ela teria a circunferência aproximada de 40 mil km. Vamos considerar a maior distância possível que um sinal deve percorrer no planeta, portanto vamos dividir a circunferência por dois e chegamos a 20 mil km aproximadamente. Sinais elétricos atingem a velocidade da luz, que é aproximadamente de 300 mil km/s. O que isso significa? Que um sinal percorre meia circunferência terrestre em pouco menos de 100 ms. Isso... não parece muito, né? Errado! É muito sim. Considere a quantidade de trocas de informação que precisam acontecer (indo e voltando) para que um simples site seja carregado e considere, também, que um sinal jamais vai percorrer toda essa extensão sem passar por pelo menos uma dezena de roteadores/servidores de DNS. O resultado? De fato, temos situações em que há um gap de resposta entre o cliente e o servidor que é absolutamente incompatível com as demandas de usabilidade da internet.
Qual a solução, então? Óbvio! Ter um (ou mais) servidores em cada um dos
continentes do planeta! Isso pareceu tão proibitivo para você quanto para mim?
É porque, para a maioria das empresas, isso é absolutamente proibitivo. Entram
na jogada os nossos bilionários odiados favoritos com suas infraestruturas de
servidores globais e uma vontade de tornar mais da metade das empresas que
trabalham com computação em viciados por IaaS e temos a solução para esse
problema!
No parágrafo acima mencionei o acrônimo IaaS. Pesquise o que esse acrônimo significa e como ele se relaciona com computação em nuvem. Aproveite e pesquise mais os seguintes acrônimos:
- PaaS; e
- SaaS.
O paradigma de computação em nuvem se destaca por oferecer soluções complexas sem transparecer essa complexidade para o usuário final e tipicamente em um modelo pay as you go, em que você paga apenas pelo que de fato usa.
Vamos ser sinceros, vocês todos já estão viciados em computação em nuvem (exatamente como os nossos queridos bilionários planejaram). Eu não preciso ficar contando para vocês o que torna o paradigma da AWS/Azure/GCP únicos, né? Vamos seguir em frente!
Temos mais dois paradigmas importantes para abordar:
- Computação em névoa (Fog computing); e
- Computação na borda (Edge computing).
Mas essas duas são tão importantes para esse módulo que merecem uma seção só para elas, então clica ali no link da próxima seção que eu explico para você.