Conjuntos de instruções
As duas principais arquiteturas usadas em processadores modernos são a x86 e ARM, mas, no que se predicam essas diferenças arquiteturais? O que exatamente alguém deve compreender quando quer entender a diferença entre duas arquiteturas de CPUs? Antes de mergulharmos nas arquiteturas específicas, vamos conversar sobre um dos aspectos mais importantes na hora de se criar um novo processador: o conjunto de instruções.
1. Composição da instrução
Section titled “1. Composição da instrução”A pergunta fundamental para entender a composição de uma instrução é: o que é necessário para que um processador consida computar algo?
Ora, é necessário definir:
- A operação a ser feita;
- O(s) operando(s) que compõe a operação;
- Um destino para o resultado da operação; e
- Uma referência para a próxima operação que deve ser executada.
Esses quatro elementos são fundamentais para aplicar o conceito de máquina computacional definido por Von Neumann. Nota-se, no entanto, que alguns deles por vezes serão implícitos - isto é, não será necessário definí-los explicitamente -, como por exemplo a referência à próxima operação, que normalmente é feita apenas incrementando o endereço da operação anterior em memória através do Program Counter.
Os elementos que quase nunca são implícitos em uma instrução são o código da operação (opcode) e uma referência a um ou mais operandos. A imagem abaixo exemplifica uma típica palavra de instrução de CPU. Nota-se que uma das escolhas possíveis é quanto espaço se reserva para o opcode e para os operandos e essa decisão impacta diretamente na construção arquitetural do componente, tendo em vista que invariavelmente essa instrução precisa ser armazenada no instruction register e processada no circuito de controle de modo a executar as microinstruções necessarias para o funcionamento da CPU.

Já deve ter ficado claro, aliás, que após o ciclo de fetch, que sempre é igual não importa para qual instrução, o que é feito no ciclo de execute varia de acordo com o tipo de instrução que deve ser executada. Segue, então , que outra das decisões de projeto importantes de uma CPU envolve os tipos de instruções por ela suportadas.
2. Tipos de instruções
Section titled “2. Tipos de instruções”Os tipos de instruções de uma CPU podem ser divididas em:
- Transferência de dados
- Aritmética
- Lógica
- Conversão
- Entrada e Saída
- Controle de sistema
- Transferência de controle
As instruções de Aritmética e Lógica são, de certo modo, autoexplicativas. Tratam-se das operações básicas que a CPU é capaz de fazer e já foram abordadas de modo geral nos exemplos do IAS e do SAP.
As instruções de Transferência de dados, por sua vez, viabilizam o transporte de dados entre registradores da CPU e a memória principal do sistema.
As instruções de Entrada e Saída apresentam a principal forma de interação de uma CPU com seus periféricos. Por outro lado, as instruções de Transferência de controle servem tanto para chamada de subrotinas como para tratar interrupções Por outro lado, as instruções de Transferência de controle servem tanto para chamada de subrotinas como para tratar interrupções do processador e saltos condicionais ou incondicionais.
As instruções de Controle de sistema representam operações que só podem ser executadas em um estado chamado de supervisor. Essas instruções são reservadas para o uso do kernel dos sistemas operacionais e garantem acesso a uma série de registradores utilizados para garantir a prioridade de segurança dos processos executados a nível de kernel.
Por fim, as instruções de Conversão são usadas quando é necessário traduzir um tipo de dado para outro. Por exemplo, quando é necessário converter um número de ponto flutuante para inteiro ou vice versa.
3. Tipos de dados
Section titled “3. Tipos de dados”Os tipos de dados utilizados em uma instrução de CPU não fogem muito daqueles que já estamos acostumados a usar em uma típica linguagem de programação. Na verdade, há bem mais restrições nesse aspecto. Sendo assim, essa seção vai ser um tanto curta. Os tipos de dados em uma instrução são dividos em:
- Endereços
- Valores numéricos
- Caracteres
- Palavras lógicas (na forma de conjuntos de bits sem uma interpretação coesa)
O que requer um pouco mais de nossa atenção é o endereçamento de operandos.
4. Tipos de endereçamento
Section titled “4. Tipos de endereçamento”Uma das questões mais interessantes de se analisar em um conjunto de instruções são os diferentes modos de endereçamento possíveis. De modo geral, eles se dividem em:
- Imediato
- Direto
- Indireto
- Por registrador
- Indireto por registrador
- Por deslocamento
- De pilha
O endereçamento imediato é o mais simples de entender. Trata-se do operando sendo utilizado diretamente na instrução.
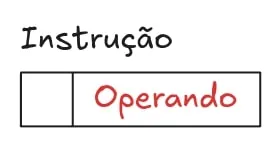
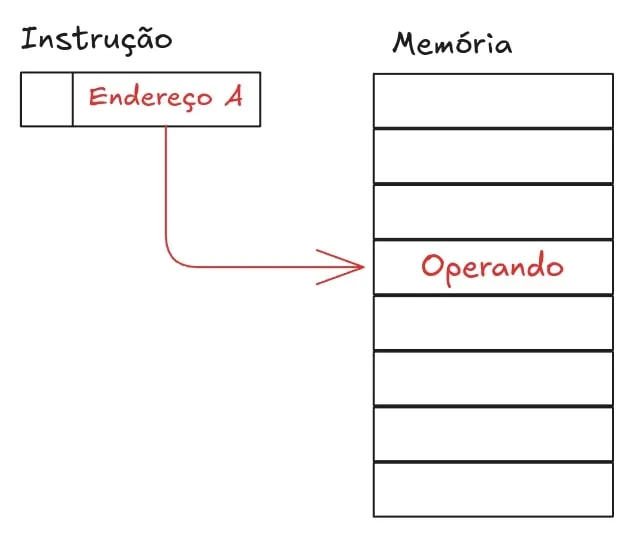
O endereçamento direto é quase tão simples quanto. Quando é usado, a instrução recebe o endereço do operando para ser procurado na memória principal do sistema.
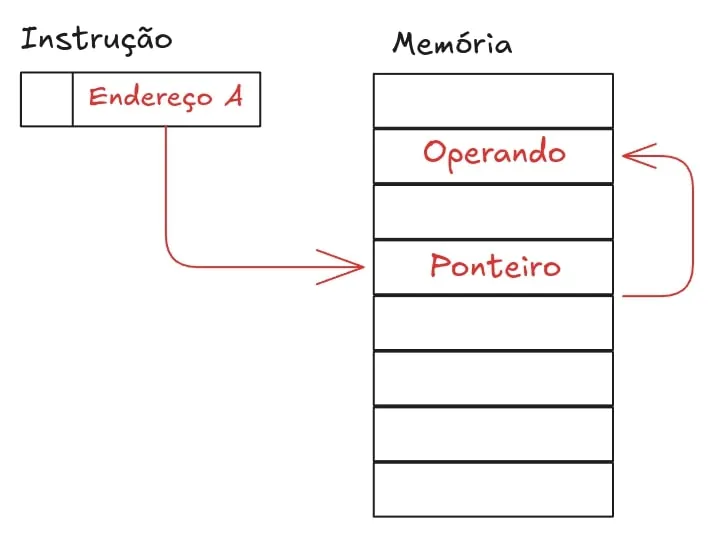
A seguir, temos o endereçamento indireto. Quando é usado, a instrução recebe um endereço na memória principal que aponta para outro local, onde de fato pode ser encontrado o operando.
Se isso te parece uma complicação desnecessária, considere o seguinte exemplo:
Digamos que temos um espaço de 4 bits na instrução para a referência ao operando. Com esses 4 bits, podemos representar 8 valores numéricos distintos se usarmos endereçamento imediato.
Digamos que temos uma memória cuja largura da página é de 8 bits. Nesse caso, quando escolhemos o endereçamento direto passamos a conseguir referenciar 8 endereços que contem valores numéricos com 256 possibilidades distintas. O ganho aqui é claro.
No entanto, o que acontece se nossa memória tiver mais do que apenas 8 endereços disponíveis? Digamos que tenhamos 126 endereços distintos na memória principal do dispositivo. Nesse caso, conseguiriamos apenas referenciar por endereçamento direto as informações que ficam nos endereços de 0 a 7. Como poderíamos resolver esse problema? Simples: basta usar o endereçamento indireto. Assim, usamos os primeiros 8 endereços da memória para guardar ponteiros e esses ponteiros são capazes de apontar para qualquer outro lugar na memória principal, já que a largura da página é de 8 bits.
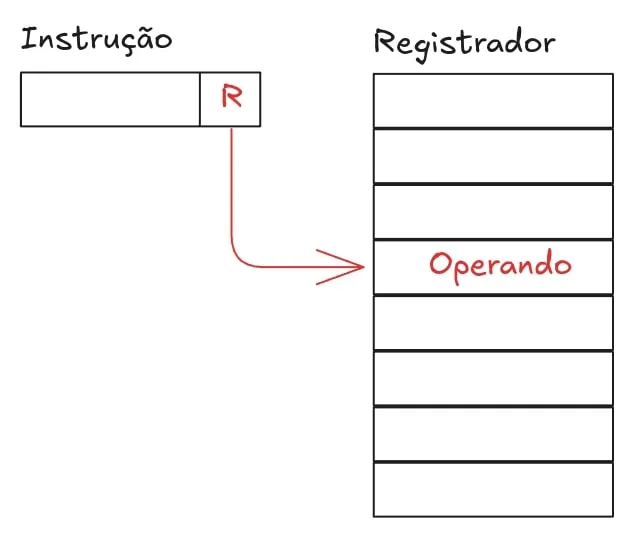
A seguir, temos o endereçamento por registrador direto e indireto. Aqui temos o mesmo conceito dos endereçamentos direto e indireto, só que utilizando um registrador. Essa escolha tem duas vantagens e uma desvantagem:
- Os registradores são muito mais rápidos
- Precisa-se de menos bits para endereçamento de registradores, mas isso só é possível pois
- Há be menos registradores disponíveis do que espaços de memória em um sistema típico.
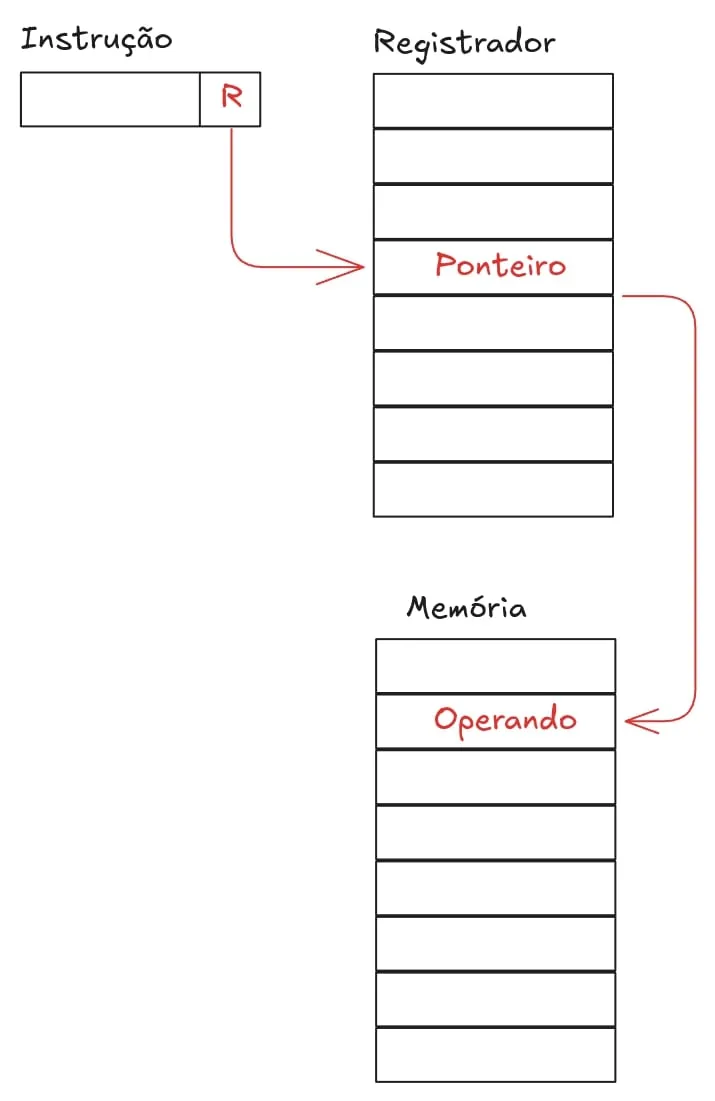
A seguir, temos o endereçamento por deslocamento
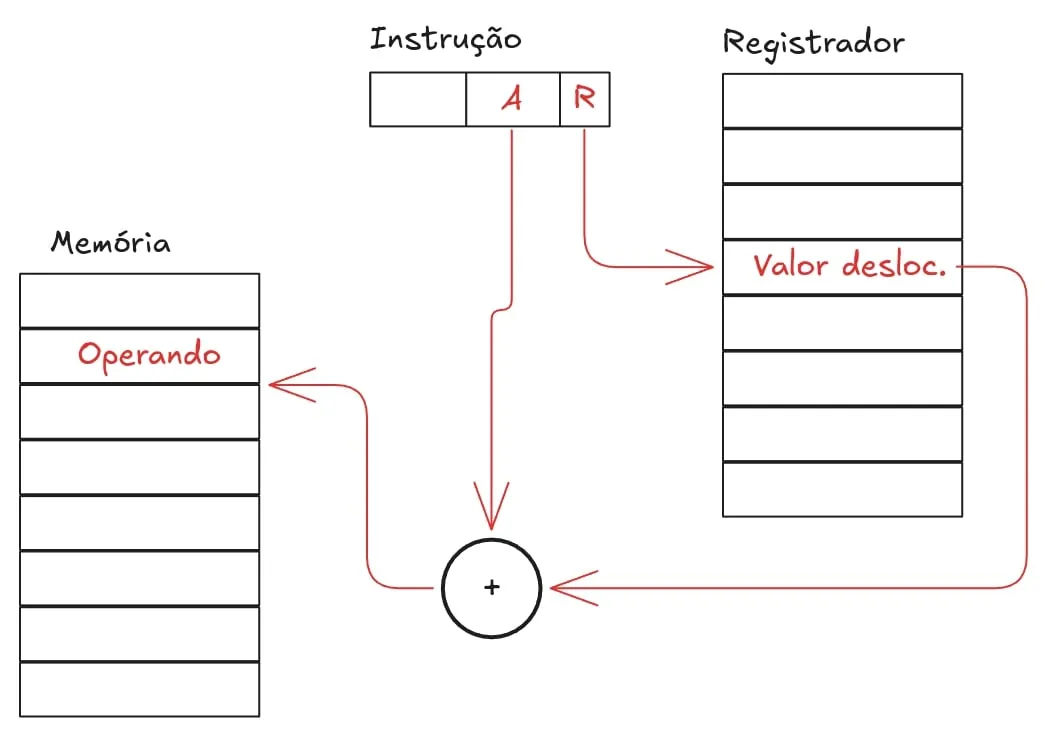
Para entender sua utilidade, considere como é a implementação típica de um array. Trata-se de um endereço base, a partir do qual todos os outros valores podem ser acessados a partir de incrementos desse endereço base.
Por fim, temos o endereçamento de pilha. Este é um tipo de endereçamento implícito, isto é, não precisamos definir um endereço na instrução. Sempre que uma operação usa esse tipo de endereçamento, fica implícito que o operando a ser utilizado é aquele que está no topo da pilha do processador.
Antes de seguirmos para a análise das arquiteturas x86 e ARM, vamos dedicar um tempo para discutir uma estratégia muito útil para otimizar o tempo de espera das CPUs durante sua operação: o pipelining.