Microsserviços
Pessoal aqui vamos fazer uma análise do que são estes tipos de padrão de arquitetura de serviços. Tanto monolítica quanto de microsserviços.
1. Arquitetura de Software
Section titled “1. Arquitetura de Software”Podemos definir arquitetura de software como:
Arquitetura de software refere-se ao conjunto de estruturas necessárias para racionalizar o desenvolvimento, a manutenção e a operação de um sistema de software. Ela envolve a definição de componentes de software, suas propriedades externas, e as relações entre eles.
Acho que é relevante verificarmos a definição de arquitetura de software, fornecida por Martin Fowler, compartilhada por Ralph Johnson. Segundo ele, arquitetura de software é:
“Architecture is about the important stuff. Whatever that is”.
“Murilão, por que é importante conhecer o que é arquitetura de software?”
Aqui temos uma pergunta excelente! Não podemos simplesmente escrever software e entregar e tudo resolvido? Vamos pensar em algumas coisas aqui. Por mais que essa definição funcione bem para construção de pequenas soluções, vamos pensar em uma solução um pouco maior ou ainda em sistemas que serão desenvolvidos por diversos programadores ou ainda precisa de manutenção por tempo mais longo (não será um projeto entregue e terminado).

Legal, agora pensando mais neste processo. Como vamos conseguir organizar o que está sendo desenvolvido? Ainda mais, como vamos separar as responsabilidades (melhor ainda, as funcionalidades) que cada elemento que deve ser implementado?
Pessoal essas são algumas dúvidas que vão começar a surgir quando começamos a pensar na estrutura do nossos projetos. Chamo a atenção que este é um processo. Muitas vezes, vamos estar focados na entrega e como dominar melhor esse processo, com uma tecnologia ou ferramenta. Minha sugestão para esses casos é sempre manter claro o que está sendo desenvolvido e qual o limite da solução que está sendo implementada. Se você está implementando, neste momento, um CRUD, tente conhecer as outras partes que existem no sistema que você está trabalhando.
Uma definição bastante interessante e rica do conceito de arquitetura de software e engenharia de software é que elas caracterizam a consolidação da abstração. Pensar na arquitetura de um sistema, é pensar neste sistema daqui a vários anos e como ele deve se comportar.
Vamos avaliar agora alguns princípios da arquitetura de software.
2. Princípios de Arquitetura de Software
Section titled “2. Princípios de Arquitetura de Software”2.1. Princípio da Responsabilidade Única (Single Responsibility Principle – SRP)
Section titled “2.1. Princípio da Responsabilidade Única (Single Responsibility Principle – SRP)”-
Definição e Racional Cada módulo (classe, componente ou serviço) deve concentrar-se em uma única responsabilidade ou propósito de negócio. Em outras palavras, deve haver apenas uma razão para que esse módulo mude ao longo do tempo.
-
Por que é importante?
- Facilita a Manutenção: Quando um módulo tem apenas uma responsabilidade, as alterações exigidas por mudanças no domínio de negócio ou nos requisitos impactam uma única parte do sistema, reduzindo o risco de efeitos colaterais inesperados.
- Melhora a Legibilidade e o Entendimento: Desenvolvedores que leem o código conseguem rapidamente identificar “o que cada parte faz” sem precisar vasculhar lógica de domínios não relacionados.
- Facilita Testes Unitários: Um módulo com uma única responsabilidade tende a ter menos cenários de teste e dependências, tornando seus testes mais precisos, isolados e de mais fácil manutenção.
-
Exemplo Imagine um “Gerenciador de Pedidos” (
OrderManager) que faz desde cálculo de valores, validação de estoques, geração de nota fiscal até envio de e-mails de confirmação. Esse acoplamento de responsabilidades prejudica a evolução. Seguindo o SRP, separaríamos, por exemplo:OrderCalculator→ somente lógica de cálculo de preço, descontos e impostos.StockValidator→ valida se há estoque em todas as etapas.InvoiceGenerator→ gera e armazena a nota fiscal em sistema fiscal.NotificationSender→ envia e-mail, SMS ou notificação ao cliente.
Em vez de ter uma classe que faz tudo (cálculo de preço, validação de estoque, geração de nota fiscal e envio de e-mail), quebramos em componentes separados, cada um com uma única responsabilidade.
class OrderCalculator: def calculate_total(self, items): """ items: lista de tuplas (preco_unitario: float, quantidade: int) """ total = sum(price * qty for price, qty in items) # Aqui poderíamos incluir regras de desconto, impostos etc. return totalclass StockValidator: def __init__(self, inventory_service): self.inventory_service = inventory_service
def validate(self, items): """ items: lista de tuplas (sku: str, quantidade: int) """ for sku, qty in items: if not self.inventory_service.has_stock(sku, qty): raise ValueError(f"Sem estoque para o produto {sku}") return Trueclass InvoiceGenerator: def __init__(self, fiscal_api_client): self.fiscal_api_client = fiscal_api_client
def generate(self, order_id, customer_id, total_amount): """ Gera nota fiscal via API externa e retorna URL ou número da nota. """ nf_data = { "order_id": order_id, "customer_id": customer_id, "amount": total_amount, } response = self.fiscal_api_client.create_invoice(nf_data) return response.get("invoice_number")class NotificationSender: def __init__(self, email_service, sms_service=None): self.email_service = email_service self.sms_service = sms_service
def send_order_confirmation(self, customer_email, order_id): subject = f"Confirmação do Pedido #{order_id}" body = f"Seu pedido {order_id} foi recebido com sucesso!" self.email_service.send_email(customer_email, subject, body)
def send_sms_update(self, customer_phone, message): if not self.sms_service: return self.sms_service.send_sms(customer_phone, message)class OrderManager: def __init__( self, calculator: OrderCalculator, validator: StockValidator, invoice_gen: InvoiceGenerator, notifier: NotificationSender, ): self.calculator = calculator self.validator = validator self.invoice_gen = invoice_gen self.notifier = notifier
def place_order(self, order_id, customer_id, customer_email, items): """ items: lista de dicionários, ex: [ {"sku": "ABC", "qty": 2, "price": 10.0}, {"sku": "XYZ", "qty": 1, "price": 20.0}, ] """ # 1. Valida estoque sku_qty_list = [(item["sku"], item["qty"]) for item in items] self.validator.validate(sku_qty_list)
# 2. Calcula total price_list = [(item["price"], item["qty"]) for item in items] total = self.calculator.calculate_total(price_list)
# 3. Gera nota fiscal invoice_number = self.invoice_gen.generate(order_id, customer_id, total)
# 4. Envia notificação ao cliente self.notifier.send_order_confirmation(customer_email, order_id)
return {"order_id": order_id, "total": total, "invoice": invoice_number}Aqui, OrderManager apenas faz as chamadas das responsabilidades individuais.
2.2. Princípio Aberto/Fechado (Open/Closed Principle – OCP)
Section titled “2.2. Princípio Aberto/Fechado (Open/Closed Principle – OCP)”-
Definição e Racional Os módulos, classes ou componentes devem estar abertos para extensão (podemos adicionar comportamentos) mas fechados para modificação direta (não devemos alterar código-fonte existente toda vez que precisamos de nova funcionalidade).
-
Por que é importante?
- Reduz Riscos de Regressão: Alterar código já testado pode introduzir bugs em funcionalidades existentes. Se pudermos estender sem modificar, mantemos o sistema estável e confiável.
- Promove Reutilização e Evolução do Código: É possível compor novas funcionalidades a partir de extensões (subclasses, estratégias, decorators) sem precisar editar a base.
-
Estratégias Comuns
- Herança/Polimorfismo: Criar subclasses ou interfaces que implementam comportamentos específicos.
- Injeção de Dependência e Padrões de Projeto: Utilizar padrões como Strategy, Decorator ou Template Method para variar algoritmos sem modificar a classe base.
- Plug-in/Arquitetura de Módulos: Permitir que novos módulos sejam registrados dinamicamente, desde que sigam contratos (interfaces) definidos.
-
Exemplo Suponha um sistema de geração de relatório que, inicialmente, gera apenas relatórios em PDF. Para adicionar relatórios em Excel, ao invés de editar a classe
PdfReportGenerator, definimos uma interfaceReportGeneratore criamos classesPdfReportGeneratoreExcelReportGenerator. O consumidor (camada de aplicação) solicita a interface e recebe a implementação adequada, sem alterar o gerador PDF já existente. Definimos uma abstração (ReportGenerator) e depois estendemos sem alterar o código existente.report_generator.py
from abc import ABC, abstractmethod
class ReportGenerator(ABC): @abstractmethod def generate(self, data): """ Gera relatório a partir de ‘data’ (por exemplo, lista de dicionários). Deve retornar um objeto ou arquivo correspondente (bytes, caminho em disco etc.). """ pass
```pythonfrom report_generator import ReportGenerator
class PDFReportGenerator(ReportGenerator): def generate(self, data): # Implemente geração de PDF (biblioteca como ReportLab, FPDF etc.) pdf_content = f"Relatório PDF: {data}" # Exemplo simplificado return pdf_content.encode("utf-8")from report_generator import ReportGenerator
class ExcelReportGenerator(ReportGenerator): def generate(self, data): # Implemente geração de Excel (biblioteca como openpyxl, xlsxwriter etc.) excel_content = f"Relatório Excel: {data}" # Exemplo simplificado return excel_content.encode("utf-8")def export_report(generator: ReportGenerator, data): arquivo = generator.generate(data) # Salvar em disco, enviar por e-mail, etc. return arquivo
# Uso:data = [{"campo": "valor1"}, {"campo": "valor2"}]pdf_gen = PDFReportGenerator()relatorio_pdf = export_report(pdf_gen, data)
excel_gen = ExcelReportGenerator()relatorio_excel = export_report(excel_gen, data)Por que OCP aqui?
- export_report lida apenas com a interface ReportGenerator.
- Quando adicionamos ExcelReportGenerator, não precisamos tocar em export_report nem em PDFReportGenerator. Basta criar uma nova classe que implemente ReportGenerator.
2.3. Princípio da Substituição de Liskov (Liskov Substitution Principle – LSP)
Section titled “2.3. Princípio da Substituição de Liskov (Liskov Substitution Principle – LSP)”-
Definição e Racional As subclasses ou tipos derivados devem ser substituíveis por suas classes base sem alterar propriedades desejáveis do programa (correção, desempenho, segurança, etc.). Ou seja, se
ClasseBestende/delega funcionalidades deClasseA, então um objeto deClasseBdeve comportar-se de modo compatível comClasseA. -
Por que é importante?
- Coerência de Herança: Garante que hierarquias de classe sejam consistentes; elimina surpresas de comportamento inesperado.
- Facilita Polimorfismo Seguro: Permite trocar implementações derivadas em tempo de execução sem quebrar regras de negócio.
-
Condições Gerais
- Pré-condições não podem ser fortalecidas na classe derivada (não podemos exigir mais do cliente do que a classe base exigia).
- Pós-condições não podem ser enfraquecidas (a classe derivada deve entregar, no mínimo, o que a base prometia).
- Invariantes definidas pela classe base devem permanecer válidas na derivada.
-
Exemplo Se temos um método
processPayment(PaymentMethod pm), eCreditCardPaymentePaypalPaymentherdam dePaymentMethod, então, ao chamarprocessPaymentcom uma instância dePaypalPayment, o sistema deve comportar-se da mesma forma que se fosse umCreditCardPayment, seguindo a lógica principal de “processamento de pagamento”. Se, por exemplo,PaypalPaymentlança uma exceção não prevista ou muda regras de cálculo de taxa, viola-se o LSP. Garantimos que qualquer classe derivada possa ser usada onde a base é esperada, sem quebrar comportamento.payment_method.py
from abc import ABC, abstractmethod
class PaymentMethod(ABC): @abstractmethod def process_payment(self, amount: float) -> bool: """ Processa o pagamento de um determinado valor. Retorna True se bem-sucedido, False caso contrário. """ pass
```pythonfrom payment_method import PaymentMethod
class CreditCardPayment(PaymentMethod): def __init__(self, card_number, cvv, expiry_date): self.card_number = card_number self.cvv = cvv self.expiry_date = expiry_date
def process_payment(self, amount: float) -> bool: # Lógica para processar pagamento no cartão de crédito print(f"Processando {amount} via Cartão de Crédito {self.card_number}") # Suponha sempre bem-sucedido para exemplo return Truefrom payment_method import PaymentMethod
class PaypalPayment(PaymentMethod): def __init__(self, email, token): self.email = email self.token = token
def process_payment(self, amount: float) -> bool: # Lógica para processar pagamento via PayPal print(f"Processando {amount} via PayPal {self.email}") return Truedef checkout(amount: float, payment_method: PaymentMethod): if payment_method.process_payment(amount): print("Pagamento realizado com sucesso!") else: print("Falha no pagamento. Tente novamente.")
# Uso coerente com LSP:cc = CreditCardPayment("1111-2222-3333-4444", "123", "12/25")checkout(100.0, cc) # Ok
pp = PaypalPayment("user@example.com", "token-abc123")checkout(200.0, pp) # Também ok2.4. Princípio da Segregação de Interface (Interface Segregation Principle – ISP)
Section titled “2.4. Princípio da Segregação de Interface (Interface Segregation Principle – ISP)”-
Definição e Racional “Muitas interfaces específicas são melhores do que uma interface única.” Ou seja, em vez de criar uma interface monolítica que define vários comportamentos, crie várias interfaces menores, cada uma com responsabilidade coesa.
-
Por que é importante?
- Reduz Acoplamento Indesejado: Classes que implementam a interface só precisarão conhecer (e satisfazer) métodos relevantes ao caso de uso. Evita forçar implementações vazias ou métodos irrelevantes.
- Melhora Coesão: Cada interface agrupa métodos relacionados por funcionalidade, facilitando a leitura e manutenção.
-
Exemplo Em vez de uma interface única que define vários métodos não relacionados, criamos interfaces pequenas e específicas.
interfaces.py
from abc import ABC, abstractmethod
class Printer(ABC): @abstractmethod def print_document(self, content: str) -> None: pass
class Scanner(ABC): @abstractmethod def scan_document(self) -> str: pass
class Fax(ABC): @abstractmethod def fax_document(self, content: str, fax_number: str) -> bool: pass
```pythonfrom interfaces import Printer
class BasicPrinter(Printer): def print_document(self, content: str) -> None: print(f"Imprimindo: {content}")from interfaces import Printer, Scanner, Fax
class MultiFunctionDevice(Printer, Scanner, Fax): def print_document(self, content: str) -> None: print(f"[MFP] Imprimindo: {content}")
def scan_document(self) -> str: scanned_text = "Conteúdo escaneado." print(f"[MFP] Digitalizando: {scanned_text}") return scanned_text
def fax_document(self, content: str, fax_number: str) -> bool: print(f"[MFP] Enviando fax para {fax_number}: {content}") return Truefrom basic_printer.py import BasicPrinterfrom multi_function_device.py import MultiFunctionDevice
printer = BasicPrinter()printer.print_document("Relatório de vendas") # Funciona
mfp = MultiFunctionDevice()mfp.print_document("Contrato") # OKtext = mfp.scan_document() # OKmfp.fax_document("Página 1", "+5511999999999") # OKPor que ISP?
- Se tivéssemos só uma interface Device com print_document, scan_document, fax_document, uma classe que só imprime seria forçada a implementar métodos vazios para scan_document e fax_document.
- Ao segregar, BasicPrinter implementa apenas o que interessa, e MultiFunctionDevice implementa todas.
2.5. Princípio da Inversão de Dependência (Dependency Inversion Principle – DIP)
Section titled “2.5. Princípio da Inversão de Dependência (Dependency Inversion Principle – DIP)”-
Definição e Racional
- Módulos de alto nível não devem depender de módulos de baixo nível. Ambos devem depender de abstrações (interfaces, classes abstratas).
- Abstrações não devem depender de detalhes. Detalhes (implementações concretas) devem depender de abstrações.
-
Por que é importante?
- Desacoplamento: Camadas de alto nível (regras de negócio) não conhecem implementações concretas de baixo nível (bancos de dados, frameworks, bibliotecas), apenas interfaces. Isso torna possível trocar implementações sem alterar lógica principal.
- Facilita Testes: Com injeção de dependências, podemos “mockar” repositórios, serviços externos ou adaptadores, testando apenas a lógica de negócio sem dependências reais.
-
Exemplo Separamos a camada de negócio da implementação concreta do repositório, invertendo dependência para interfaces (abstrações).
order_repository.py from abc import ABC, abstractmethodclass OrderRepository(ABC):@abstractmethoddef save(self, order) -> None:pass@abstractmethoddef find_by_id(self, order_id) -> dict:passmysql_order_repository.py from order_repository import OrderRepositoryclass MySqlOrderRepository(OrderRepository):def __init__(self, connection):self.connection = connection # ex.: objeto de conexão SQLAlchemy ou pymysqldef save(self, order) -> None:# Implemente inserção no MySQLcursor = self.connection.cursor()cursor.execute("INSERT INTO orders (id, customer_id, total) VALUES (%s, %s, %s)",(order["id"], order["customer_id"], order["total"]),)self.connection.commit()def find_by_id(self, order_id) -> dict:cursor = self.connection.cursor()cursor.execute("SELECT id, customer_id, total FROM orders WHERE id = %s", (order_id,))row = cursor.fetchone()if row:return {"id": row[0], "customer_id": row[1], "total": row[2]}return Noneorder_service.py class OrderService:def __init__(self, repository: OrderRepository):self.repository = repositorydef create_order(self, order_data: dict) -> None:# Exemplo de lógica de negócio: atribuir timestamp, validar dados etc.self.repository.save(order_data)def get_order(self, order_id) -> dict:return self.repository.find_by_id(order_id)main.py # Suponha que 'mysql_connection' seja uma conexão configuradafrom mysql_order_repository import MySqlOrderRepositoryfrom order_service import OrderServicemysql_repo = MySqlOrderRepository(mysql_connection)service = OrderService(mysql_repo)novo_pedido = {"id": 1, "customer_id": 42, "total": 100.0}service.create_order(novo_pedido)print(service.get_order(1))
Por que DIP aqui?
- OrderService não depende de MySqlOrderRepository diretamente, mas sim da abstração OrderRepository.
- Se quisermos trocar para InMemoryOrderRepository (por testes), basta passar outra implementação sem alterar OrderService.
2.6. Princípio da Convenção sobre Configuração (Convention over Configuration)
Section titled “2.6. Princípio da Convenção sobre Configuração (Convention over Configuration)”-
Definição e Racional Sempre que possível, adote convenções de nomenclatura, estrutura de pastas, formatação ou padrão de comportamento já consagrados pela comunidade ou framework. Dessa forma, o desenvolvedor só precisará configurar algo quando for “fora do padrão”.
-
Por que é importante?
- Reduz Sobrecarga de Configuração: Menos arquivos de configuração são necessários, diminuindo chances de erro e facilitando onboarding de novos desenvolvedores.
- Padrões Óbvios: Quando todo mundo conhece a convenção (por exemplo, “controllers ficam em
src/controllers, views emsrc/views”), diminui-se a aprendizagem sobre onde buscar artefatos.
-
Exemplo
- Ruby on Rails: Se você cria
app/models/user.rb, o Rails pressupõe que existe uma tabelausersno banco de dados e que a classe se chamaUser. - Spring Boot: Estrutura de pacotes como
com.exemplo.app.controller,com.exemplo.app.service,com.exemplo.app.repositorysegue convenções que permitem autoconfiguração automática (component scanning). - Node.js (Express + Sequelize): Modelos nomeados em PascalCase correlacionados com tabelas em snake_case (e.g.,
UserAccount→ tabelauser_accounts). - Python: Não há um “código específico” para este princípio, mas a ideia em Python é observar práticas amplamente adotadas. Exemplos de “convenções”:
- Ruby on Rails: Se você cria
- Estrutura de Pastas:
projeto/ ├── app/ │ ├── __init__.py │ ├── models.py │ ├── views.py │ ├── controllers.py │ └── services.py ├── requirements.txt └── run.pyFerramentas como Flask podem “descobrir” onde estão os blueprints ou views se você usar nomes padronizados.
- Nomeação de Classes e Módulos:
snake_casepara módulos (order_service.py), PascalCase para classes (OrderService).snake_casepara funções e variáveis.
- Configuração Padrão em Frameworks:
- Em Django, se você criar um app chamado blog, o Django automaticamente procura em blog/models.py e blog/views.py.
- Em FastAPI, se você cria app/main.py com variável app = FastAPI(), ao executar uvicorn app.main:app, por convenção ele monta a aplicação.
-
Cuidados
- Convenções diferentes em projetos distintos podem gerar confusão; escolha e documente claramente as convenções do seu time.
2.7. Princípio do Menor Conhecimento (Least Knowledge Principle – LKP, também conhecido como Law of Demeter)
Section titled “2.7. Princípio do Menor Conhecimento (Least Knowledge Principle – LKP, também conhecido como Law of Demeter)”-
Definição e Racional Um objeto deve interagir apenas com “amigos imediatos” (objetos diretamente relacionados) e não conhecer demais estruturas internas de outros objetos (“não fale com estranhos”). A regra prática: uma chamada não deve “encadear” muitas chamadas para acessar propriedades ou métodos de objetos externos.
-
Por que é importante?
- Reduz Acoplamento: Se objetos dependem apenas de métodos públicos de seus colaboradores diretos, mudanças em estruturas internas de outros objetos não impactam tanto seu código.
- Melhora Legibilidade e Segurança: Torna claro “quem faz o quê” sem necessidade de navegar em camadas profundas de chamadas.
-
Exemplo Suponha
order.getCustomer().getAddress().getCity(). Para seguir o LKP, seria preferível queOrderexpusesse um métodogetCustomerCity(), ocultando detalhes de relacionamento entreCustomereAddress. Assim, se a estrutura interna deAddressmudar,Orderpode adaptar sem que a camada chamadora perceba.Em vez de encadear muitas chamadas, expomos operações “diretas” no objeto, diminuindo o conhecimento sobre estruturas internas.
# suponha que exista uma hierarquia: Order -> Customer -> Address -> Cityclass City:def __init__(self, name):self.name = nameclass Address:def __init__(self, city: City):self.city = cityclass Customer:def __init__(self, address: Address):self.address = addressclass Order:def __init__(self, customer: Customer):self.customer = customerdef get_customer(self):return self.customer# Em algum outro ponto do código:order = Order(Customer(Address(City("São Paulo"))))city_name = order.get_customer().address.city.name # Encadeamento excessivoprint(city_name)class Order:def __init__(self, customer: Customer):self.customer = customerdef get_customer_city(self):# Expõe apenas o que é relevante para quem chama Orderreturn self.customer.address.city.name# Uso simplificado:order = Order(Customer(Address(City("Rio de Janeiro"))))print(order.get_customer_city()) # Cliente só precisa saber de 'get_customer_city'Por que isso importa?
Se a estrutura interna de Address mudar (por exemplo, Address agora armazena city de forma diferente), só ajustamos get_customer_city() em Order e não precisaremos mudar todos os pontos que faziam order.get_customer().address.city.name.
2.8. Princípio do Encapsulamento
Section titled “2.8. Princípio do Encapsulamento”-
Definição e Racional Cada objeto deve ser responsável por manter seu próprio estado interno e não permitir que outras partes do sistema modifiquem diretamente suas variáveis internas. O acesso ao estado deve ocorrer por meio de métodos públicos ou interfaces bem definidas, garantindo que invariantes sejam preservadas.
-
Por que é importante?
- Protege Invariantes de Domínio: Garante que o objeto só aceite operações válidas, impedindo que seu estado fique inconsistente.
- Oculta Implementação: Caso seja necessário alterar a estrutura interna ou a representação de dados, a interface exposta aos clientes mantém-se a mesma.
- Segurança e Manutenção: Reduz efeitos colaterais inesperados e facilita a refatoração de implementações internas.
-
Exemplo Uma classe
BankAccountnão deve expor seu saldo (balance) como variável pública. Em vez disso, métodosdeposit(amount)ewithdraw(amount)validam regras de negócio (saldo não pode ficar negativo) antes de alterar internamente o valor.
class BankAccount:def __init__(self, account_number: str, opening_balance: float = 0): self._account_number = account_number # “privado” por convenção self._balance = opening_balance # não expor atributo diretamente
@propertydef balance(self) -> float: """ Permite consulta ao saldo, mas não permite modificação direta. """ return self._balance
def deposit(self, amount: float) -> None: if amount <= 0: raise ValueError("O valor do depósito deve ser positivo.") self._balance += amount print(f"Depósito de {amount} realizado. Novo saldo: {self._balance}")
def withdraw(self, amount: float) -> None: if amount <= 0: raise ValueError("O valor do saque deve ser positivo.") if amount > self._balance: raise ValueError("Saldo insuficiente.") self._balance -= amount print(f"Saque de {amount} realizado. Novo saldo: {self._balance}")account = BankAccount("12345-6", 100.0)print(account.balance) # 100.0account.deposit(50.0) # 150.0try: account.withdraw(200.0)except ValueError as e: print(e) # "Saldo insuficiente"# Não é possível fazer: account._balance = -100 (até pode, mas viola convenção)“Caramba Murilão! Até aqui não tinha nome pior para seção né? Estamos bem longe de falar sobre microsserviços!”
Calma! Vamos chegar ai! Só quis preparar um terreno com vocês! Agora vamos lá!
3. Monolítos
Section titled “3. Monolítos”Monolitos são aplicações de software que são desenvolvidas como uma única unidade. Eles são geralmente grandes, complexos e difíceis de manter. Monolitos são frequentemente criticados por serem difíceis de escalar e manter, mas eles têm suas vantagens.
Poxa Murilo, mas por que você está falando de monolitos? A gente não está falando de microserviços?
Sim, estamos falando de microserviços, mas é importante entender o que são monolitos para entender o que são microserviços. Monolitos são a abordagem tradicional para o desenvolvimento de software, e muitas empresas ainda usam monolitos para desenvolver seus sistemas.
Mesmo que monolitos tenham suas desvantagens, eles têm suas vantagens. Monolitos são mais fáceis de desenvolver e manter do que sistemas distribuídos, e eles são mais fáceis de escalar do que sistemas distribuídos. Monolitos são uma boa escolha para sistemas pequenos e médios.
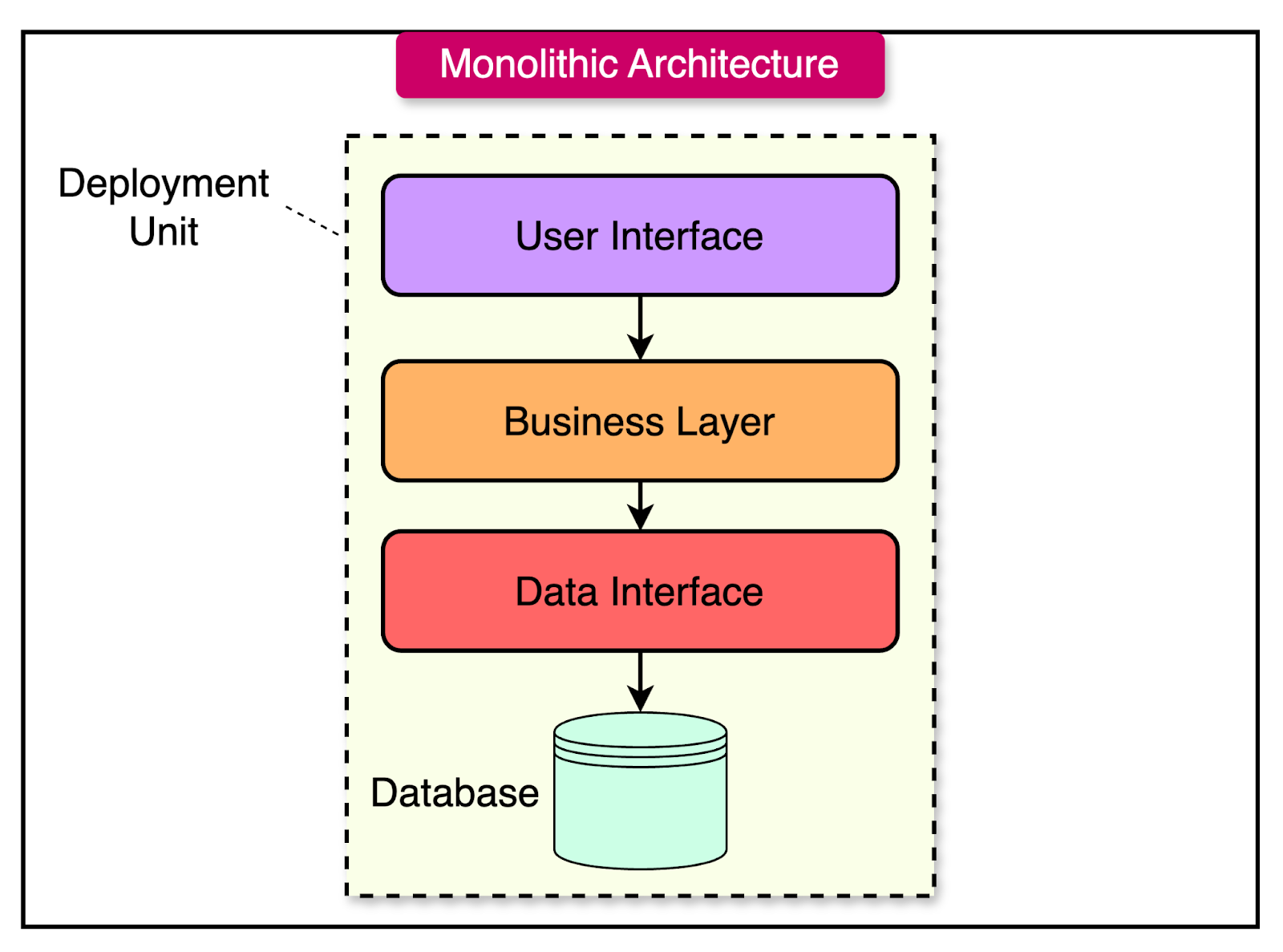
(Referência: link)
3.1 Vantagens dos Monolitos
Section titled “3.1 Vantagens dos Monolitos”Aqui estão algumas vantagens dos monolitos:
-
Simplicidade: Monolitos são mais fáceis de desenvolver e manter do que sistemas distribuídos.
-
Escalabilidade: Monolitos são mais fáceis de escalar do que sistemas distribuídos (verticalmente).
-
Facilidade de depuração: Monolitos são mais fáceis de depurar do que sistemas distribuídos, enquanto os sistemas são menores.
-
Facilidade de implementação: Monolitos são mais fáceis de implementar do que sistemas distribuídos.
-
Facilidade de teste: Monolitos são mais fáceis de testar do que sistemas distribuídos.
-
Facilidade de monitoramento: Monolitos são mais fáceis de monitorar do que sistemas distribuídos.
3.2 Desvantagens dos Monolitos
Section titled “3.2 Desvantagens dos Monolitos”Os sistemas monolíticos, nos quais o software é construído como uma única unidade indissociável, têm suas vantagens, especialmente na simplicidade de desenvolvimento e deploy inicial. No entanto, à medida que a aplicação cresce, diversas desvantagens podem se tornar aparentes. Aqui estão algumas das principais desvantagens dos sistemas monolíticos:
-
Escalabilidade limitada: Em um sistema monolítico, escalonar frequentemente significa replicar toda a aplicação, o que pode ser ineficiente se apenas partes específicas da aplicação precisarem de mais recursos. Isso resulta em uso desnecessário de recursos e pode ser custoso.
-
Dificuldade de manutenção: À medida que o monolito cresce, ele pode se tornar complexo e difícil de entender. Isso torna o processo de manutenção, como correções de bugs e adição de novas funcionalidades, mais lento e mais propenso a erros.
-
Acoplamento forte: Os componentes de um sistema monolítico são frequentemente fortemente acoplados e dependentes uns dos outros. Isso significa que mudanças em uma parte do sistema podem afetar outras partes de maneira imprevisível, aumentando o risco de falhas.
-
Implantação lenta: Atualizar um sistema monolítico pode ser um processo lento e arriscado, já que qualquer alteração requer a reimplantação de todo o sistema. Isso pode levar a tempos de inatividade significativos e reduzir a agilidade do desenvolvimento.
-
Dificuldades na adoção de novas tecnologias: Integrar novas tecnologias ou atualizar as antigas em um sistema monolítico pode ser complicado, uma vez que mudanças tecnológicas podem requerer alterações em toda a base do código.
-
Testabilidade: Testar um sistema monolítico pode ser desafiador, especialmente à medida que ele cresce. Isso ocorre porque é difícil isolar componentes para testes unitários, o que pode levar a testes integrados mais complexos e demorados.
-
Risco de falha do sistema: Em sistemas monolíticos, uma falha em um componente pode afetar toda a aplicação, resultando em falhas completas do sistema, o que pode ser catastrófico para a continuidade dos negócios.
-
Barreiras para novos desenvolvedores: Para novos desenvolvedores, entender um sistema monolítico grande e complexo pode ser intimidador e demorado, o que pode retardar o processo de integração e contribuição efetiva ao projeto.
4. Microsserviços
Section titled “4. Microsserviços”Microsserviços são uma abordagem para o desenvolvimento de software que envolve a construção de um sistema de software como um conjunto de serviços independentes. Cada serviço é uma unidade de software independente que pode ser desenvolvida, implantada e escalada de forma independente. Os microsserviços são frequentemente criticados por serem mais complexos do que monólitos, mas eles têm suas vantagens.
Ok Murilo, então estamos falando de vários pequenos monólitos?
Não exatamente. Microsserviços são diferentes de monólitos. Monólitos são uma abordagem tradicional para o desenvolvimento de software, onde todo o software é desenvolvido como uma única unidade. Microsserviços, por outro lado, são uma abordagem moderna para o desenvolvimento de software, onde o software é desenvolvido como um conjunto de serviços independentes.
“Mas o que são serviços independentes?”
Serviços independentes são serviços que podem ser desenvolvidos, implantados e escalados de forma independente. Eles são geralmente pequenos, focados em uma única tarefa e têm uma interface bem definida. Os serviços independentes são frequentemente criticados por serem mais complexos do que monolitos, mas eles têm suas vantagens.
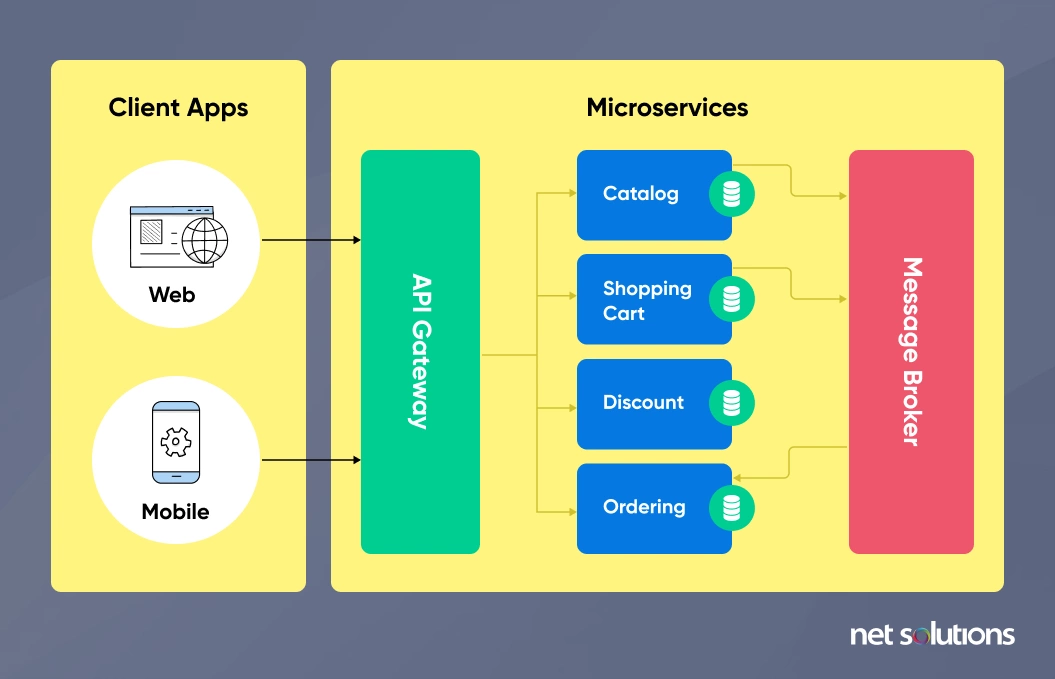
(Referência: link)
4.1 Vantagens dos Microsserviços
Section titled “4.1 Vantagens dos Microsserviços”A arquitetura de microsserviços é uma abordagem popular para o desenvolvimento de aplicações, especialmente em ambientes de grande escala e distribuídos. Aqui estão algumas das principais vantagens desta arquitetura:
-
Modularidade: Em microsserviços, cada serviço é um módulo que pode ser desenvolvido, implantado, operado e escalado de forma independente. Isso facilita a gestão de partes individuais do sistema sem afetar o todo.
-
Escalabilidade: Cada microsserviço pode ser escalado independentemente, permitindo alocar mais recursos apenas para os serviços que necessitam, o que é mais eficiente do ponto de vista de uso de recursos e custo.
-
Flexibilidade tecnológica: Diferentes microsserviços podem ser escritos em diferentes linguagens de programação, usar diferentes bancos de dados e diferentes tecnologias de armazenamento, permitindo que a equipe escolha as melhores ferramentas para cada serviço especificamente.
-
Resiliência: A falha em um microsserviço é isolada e geralmente não afeta outros serviços. Isso melhora a estabilidade geral do sistema, pois permite que apenas a parte afetada seja tratada, enquanto o restante do sistema continua operacional.
-
Facilidade de manutenção: Menos código em um serviço significa que é mais fácil de entender, testar e manter. Além disso, a autonomia dos serviços facilita a atualização e a correção de bugs em sistemas complexos.
-
Ciclos de desenvolvimento mais rápidos: Como os microsserviços são pequenos e independentes, podem ser desenvolvidos, testados e implantados mais rapidamente do que seria possível em uma arquitetura monolítica. Isso contribui para uma maior agilidade e velocidade na entrega de novas funcionalidades.
-
Deploy contínuo e independente: Os microsserviços permitem que diferentes equipes implantem seus serviços de forma independente em qualquer momento, sem interromper o funcionamento dos outros serviços. Isso facilita a integração e entrega contínuas (CI/CD).
4.2 Desvantagens dos Microsserviços
Section titled “4.2 Desvantagens dos Microsserviços”Embora a arquitetura de microsserviços ofereça muitas vantagens, existem também desafios e desvantagens significativas que devem ser consideradas antes de adotar essa abordagem. Aqui estão algumas das principais desvantagens do uso de microsserviços:
-
Complexidade de Gerenciamento: A gestão de múltiplos serviços independentes pode ser mais complexa do que gerenciar um sistema monolítico. Isso inclui desafios com versionamento de serviços, gerenciamento de dependências entre serviços e manutenção de um gateway de API eficiente.
-
Overhead de Comunicação: Como os microsserviços frequentemente se comunicam através da rede, há um overhead de latência e carga associados com as chamadas de API. Isso pode resultar em um desempenho inferior se comparado com chamadas de função em um ambiente monolítico.
-
Consistência de Dados: Manter a consistência de dados em um ambiente distribuído pode ser desafiador. Transações que abrangem múltiplos serviços exigem padrões complexos, como a compensação de transações ou o uso de transações distribuídas, que podem ser difíceis de implementar e manter.
-
Complexidade de Testes: Testar uma aplicação baseada em microsserviços pode ser mais complicado do que testar um monolito. É necessário garantir que cada serviço funcione como esperado, tanto de forma isolada quanto em conjunto com outros serviços.
-
Segurança: Aumentar o número de serviços também aumenta a superfície de ataque potencial. Cada serviço é um ponto potencial de entrada para ataques, o que requer uma abordagem robusta de segurança, autenticação e autorização entre serviços.
-
Dificuldade na Depuração e Monitoramento: Acompanhar e diagnosticar problemas em um sistema distribuído pode ser complicado, pois é necessário correlacionar logs e dados de monitoramento de vários serviços e instâncias.
-
Requisitos de Infraestrutura: Operar uma arquitetura de microsserviços geralmente requer uma infraestrutura mais sofisticada e custosa, incluindo soluções para orquestração de contêineres, monitoramento distribuído, e balanceamento de carga.
-
Custo de Desenvolvimento: O desenvolvimento pode se tornar mais caro devido à necessidade de especialistas em várias tecnologias, ferramentas adicionais para gerenciamento de microsserviços, e o esforço extra necessário para garantir a integração e a entrega contínuas.
-
Duplicação de Esforços: Pode haver uma tendência à duplicação de esforços, como funções de autenticação ou chamadas de banco de dados, em vários serviços, o que pode aumentar a carga de trabalho e os custos de manutenção.
-
Gestão de Equipes: Coordenar múltiplas equipes trabalhando em diferentes serviços pode ser desafiador, especialmente em termos de comunicação e alinhamento com os objetivos gerais do projeto.
Cada organização deve avaliar cuidadosamente esses desafios ao considerar a transição para uma arquitetura de microsserviços, garantindo que os benefícios superem as desvantagens no contexto de seus requisitos e capacidades específicos.
5. Implementações de Microsserviços
Section titled “5. Implementações de Microsserviços”Pessoal até aqui tudo muito bom, tudo muito bonito, conseguimos discutir diversos pontos conceituais sobre a aplicação de microsserviços. Agora como implementamos?
Pessoal vamos avaliar algumas formas de realizar essas implementações. Vale lembrar que existem diversas formas de implementar microsserviços, e a escolha da melhor abordagem depende do contexto e dos requisitos do projeto.
5.1 Hello World Microsserviços
Section titled “5.1 Hello World Microsserviços”Vamos criar três serviços e acessar eles através de um gateway.
Vamos criar um diretório chamado hello-world-microservices e dentro dele vamos criar três diretórios: service1, service2 e service3. Todo esse material estará no repositório do módulo.
mkdir hello-world-microservicescd hello-world-microservicesmkdir service1mkdir service2mkdir service3Para cada um dos serviços, vamos criar um arquivo Python para implementar um servidor HTTP simples que responde a uma solicitação GET com uma mensagem de “Olá, Mundo!” e o nome do serviço. Vamos utilizar o FastAPI para criar os servidores.
from fastapi import FastAPI
app = FastAPI()
@app.get("/service1")async def read_root(): return {"message": "Hello, World! from service1"}
if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8001)O código será o mesmo para os outros serviços, apenas mudando o nome do serviço. Vale destacar que vamos utilizar o uvicorn para rodar os servidores. Por hora, vamos rodar cada um dos serviços em uma porta diferente, utilizando a porta 8001 para o service1, a porta 8002 para o service2 e a porta 8003 para o service3.
Vamos ajustar o arquivo de requirements.txt para cada um dos serviços.
fastapiuvicornNovo arquivo requirements.txt para o service1 (depois da bronca).
fastapi==0.110.3uvicorn==0.29.0Agora, antes de rodarmos nossos serviços, vamos criar um dockerfile para cada um dos serviços.
# service1/Dockerfile
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
CMD ["python", "server.py"]Agora vamos construir nossa imagem e rodar nosso container.
docker build -t service1 .docker run -d -p 8001:8001 service1Vamos ter o nosso serviço rodando e agora é possível acessar ele através do endereço http://localhost:8001/service1.
Vamos fazer o mesmo para os outros serviços.
Sério Mesmo?
Poxa Murilo vamos ter que fazer isso para todos os serviços? Não tem uma forma mais fácil?
Ahhhh tem sim, vamos utilizar o docker-compose para facilitar nossa vida.
Vamos construir um arquivo docker-compose.yml na raiz do nosso projeto. A funcionalidade dele vai ser construir e rodar todos os nossos serviços.
version: '3'
services: service1: build: ./service1 ports: - "8001:8001" service2: build: ./service2 ports: - "8002:8002" service3: build: ./service3 ports: - "8003:8003"O que está acontecendo neste docker-compose é que estamos construindo e rodando os nossos serviços. Vamos rodar o comando docker-compose up na raiz do nosso projeto.
docker-compose upLegal agora todos os nossos serviços estão rodando e podemos acessar eles através dos endereços http://localhost:8001/service1, http://localhost:8002/service2 e http://localhost:8003/service3.
5.2 Gateway
Section titled “5.2 Gateway”Pessoal, vamos analisar uma coisa aqui. Nós temos três serviços rodando e cada um deles em uma porta diferente. Como podemos acessar todos esses serviços através de um único ponto de entrada?
“Murilo como assim? É só utilizar o endereço e a porta de cada um dos serviços.”
Sim, você está correto, mas imagine que você tenha um serviço que chama outros serviços e você quer que ele seja o único ponto de entrada para acessar todos os outros serviços. Ainda temos outro problema aqui, quando a nossa quantidade de serviços aumentar vamos ter que ficar atualizando o nosso cliente para acessar os novos serviços. Isso não parece ser uma boa prática. Para resolver este tipo de problema, podemos utilizar um gateway.
Vamos realizar a implementação do nosso gateway. Vamos criar um novo diretório chamado gateway e dentro dele vamos copiar os arquivos Dockerfile, server.py e requirements.txt dos nossos serviços.
Agora vamos configurar nosso gateway. Para isso vamos utilizar o Nginx para fazer o roteamento das requisições para os nossos serviços.
Vamos construir o nosso Dockerfile para o gateway.
# gateway/Dockerfile
FROM nginx:1.19.0
COPY nginx.conf /etc/nginx/nginx.confRepare que estamos fazendo levando o arquivo nginx.conf para o diretório /etc/nginx/nginx.conf do container. Dentro do arquivo nginx.conf vamos configurar o nosso gateway.
worker_processes 1;
events { worker_connections 1024; }
http { sendfile on;
upstream service1 { server service1:8001; }
upstream service2 { server service2:8002; }
upstream service3 { server service3:8003; }
server { listen 80;
location /service1 { proxy_pass http://service1; }
location /service2 { proxy_pass http://service2; }
location /service3 { proxy_pass http://service3; } }}Vamos compreender o que está acontecendo aqui:
- Estamos configurando o
Nginxpara escutar na porta80. - Estamos configurando o
Nginxpara fazer o roteamento das requisições para os serviçosservice1,service2eservice3.
Agora vamos construir a nossa imagem e rodar o nosso container.
docker build -t gateway .docker run -d -p 8000:80 gatewayAgora podemos acessar todos os nossos serviços através do endereço http://localhost:8000/service1, http://localhost:8000/service2 e http://localhost:8000/service3.
Vamos adicionar nosso serviço no nosso arquivo docker-compose.yml.
version: '3'
services: service1: build: ./service1 ports: - "8001:8001" service2: build: ./service2 ports: - "8002:8002" service3: build: ./service3 ports: - "8003:8003" gateway: build: ./gateway ports: - "8000:80"Pessoal reparem no que aconteceu aqui. Nós temos um gateway que é o único ponto de entrada para acessar todos os nossos serviços. Isso é muito interessante, pois podemos adicionar novos serviços sem precisar atualizar o nosso cliente.
5.3 Ponto de Discussão
Section titled “5.3 Ponto de Discussão”Pessoal, vamos avaliar um ponto que vale a nossa atenção: considerando a abordagem e as definições que discutimos até aqui, se um microsserviço é uma entidade de software independente, como ficam os bancos de dados?
“Murilo, cada microsserviço tem o seu próprio banco de dados?”
Essa resposta é mais complexa do que parece. Vamos avaliar algumas abordagens:
-
Banco de Dados Compartilhado: Todos os microsserviços compartilham o mesmo banco de dados. Isso pode simplificar a implementação, mas pode levar a problemas de escalabilidade e acoplamento.
-
Banco de Dados por Microsserviço: Cada microsserviço tem seu próprio banco de dados. Isso pode aumentar a complexidade, mas também pode melhorar a escalabilidade e a autonomia dos serviços.
-
Banco de Dados por Domínio: Os microsserviços são agrupados em domínios e cada domínio tem seu próprio banco de dados. Isso pode ser uma abordagem intermediária que combina os benefícios das duas abordagens anteriores.
-
Banco de Dados por Tabela: Cada microsserviço tem seu próprio esquema de banco de dados, mas compartilha o mesmo banco de dados físico. Isso pode ser uma abordagem eficiente em termos de recursos, mas pode levar a problemas de acoplamento e desempenho.
Aqui pessoal não existe uma resposta certa ou errada, a escolha da melhor abordagem depende do contexto e dos requisitos do projeto.