Gerenciamento de memória
Você já parou para pensar no que diferencia as linguagens de alto nível das linguagens de baixo nível, as chamadas linguagens de sistema? Talvez você já tenha ouvido falar do termo garbage collector e não tenha entendido exatamente o que aquilo significava ou por que isso torna linguagens mais lentas.
Para entender melhor o que tudo isso significa, vamos falar um pouco sobre memória. Para isso, vou voltar um pouco no tempo.
O modelo de von Neumann
Section titled “O modelo de von Neumann”A arquitetura de von Neumann, proposta pelo matemático John von Neumann em 1945, revolucionou a computação ao introduzir um conceito simples mas poderoso: instruções e dados devem ser armazenados na memória do dispositivo. Antes disso, os computadores eram máquinas operadas de forma quase completamente manual através de painéis de contato.
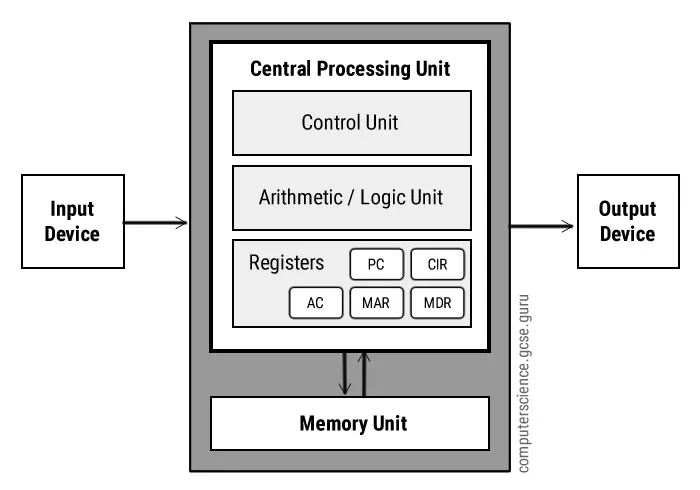
Neste modelo, a CPU busca, decodifica e executa instruções em um ciclo contínuo conhecido como fetch-decode-execute. A memória é única tanto para o programa quanto para os dados, e é endereçada diretamente pela CPU. Dispositivos de entrada e saída se comunicam com o sistema através de barramentos.
Essa quebra de paradigma se mantem até hoje e informa fortemente qualquer discussão que possamos ter sobre gerenciamento de memória em computadores. Segue que a memória, para os computadores, é fundamental tanto para armazenar instruções quanto variáveis.
Outra informação que vai informar nossa discussão sobre gerenciamento de memória em C++ é: nem toda memória é igual.
Hierarquia de memória
Section titled “Hierarquia de memória”Nem toda memória é igual. Se essa afirmação não fosse verdade, você não precisaria comprar memória RAM e um SSD para o seu sistema. Seria um ou outro.
Mesmo na época em que os computadores não caberiam na sala de estar dos apartamentos studio supervalorizados de São Paulo já existia o conceito de hierarquia de memória. Se você olhar novamente a imagem acima, da arquitetura de von Neumann, vai notar que há registradores e uma unidade de memória separada. Por quê? Não seria mais fácil ter toda a memória completamente unificada?
A resposta é simples: memória rápida é cara.
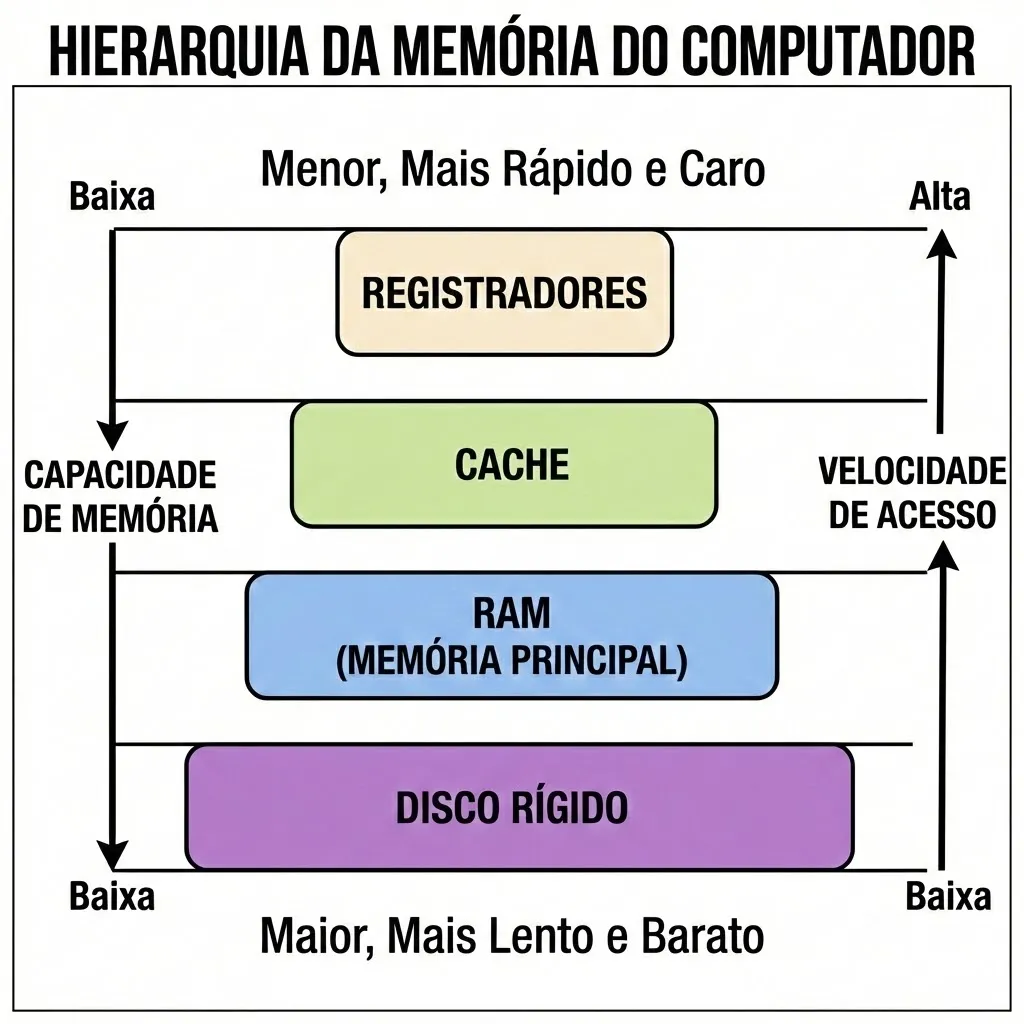
Um computador moderno tem diversos níveis de memória disponíveis:
- A CPU tem à sua disposição bancos de registradores de alta performance (AX, BX, PC, etc). Essa é a memória mais próxima do processamento e também a mais rápida. Em contrapartida, ela é mais cara e, portanto, de menor quantidade.
- Os cache L1 e L2 compõe os dois níveis de acesso rápido à variáveis para um núcleo da CPU.
- O cache L3 é um cache unificado para todos os núcleos de uma CPU. Na maioria dos casos, ele serve para diminuir o tempo necessário para operações de coerência de cache.
- A memória RAM compõe a memória principal do sistema. Sempre que ela é acessada, há uma perda de performance significativa com relação ao cache.
- O disco rígido é onde fica o armazenamento de longo prazo do computador. A sua performance é ordens de grandeza pior que até mesmo a memória RAM.
Por quê estou falando disso? Porque todos esses tipos de memória geram um problema: gerenciamento de memória. A boa notícia é que você, programador, não precisa se preocupar com o gerenciamento de memória do seu sistema. Quem precisa? Bom…
O sistema operacional
Section titled “O sistema operacional”O sistema operacional gerencia a memória através de tabelas de páginas, que são estruturas de dados que mapeiam endereços virtuais para endereços físicos da memória RAM. Cada processo possui seu próprio espaço de endereçamento virtual, isolado dos outros processos. Quando seu programa acessa um endereço de memória, o hardware de gerenciamento de memória (MMU) consulta essas tabelas para encontrar onde os dados realmente residem na memória física.
Um processo em execução organiza sua memória virtual em várias regiões distintas. A região de instruções contém o código do programa compilado. A região de dados estáticos armazena variáveis globais e estáticas que existem durante toda a execução. O stack cresce de cima para baixo, armazenando variáveis locais e informações de chamadas de função. O heap cresce de baixo para cima, fornecendo espaço para alocação dinâmica. Entre o heap e o stack existe um espaço livre que pode ser utilizado por ambos, até que se encontrem.
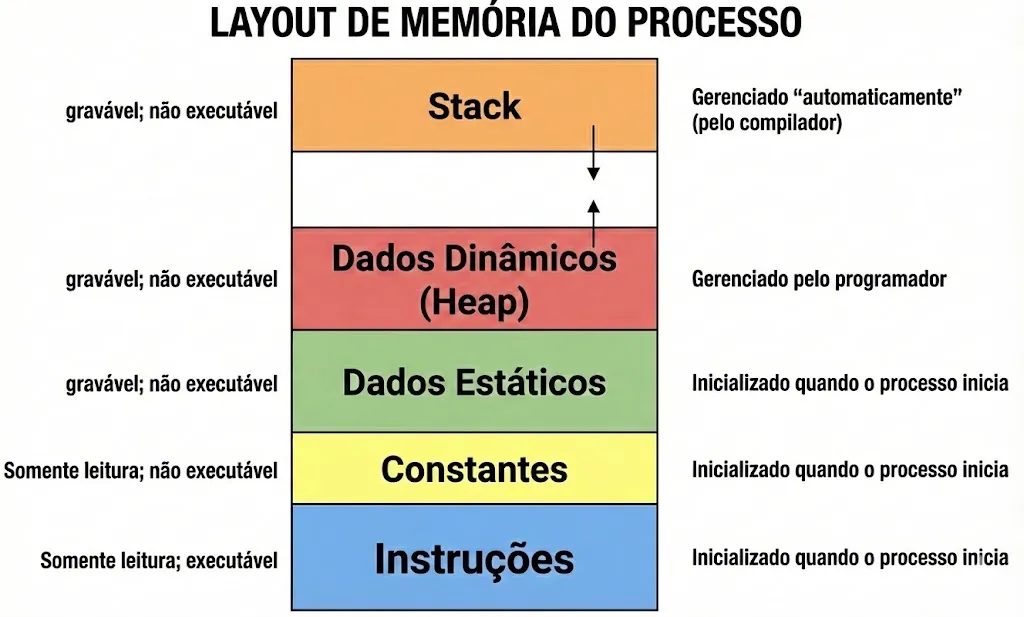
Quando um processo precisa de mais memória, o comportamento difere entre
stack e heap. O stack possui um tamanho fixo definido na criação do processo,
tipicamente entre 1 e 8 megabytes. Se uma função tentar alocar mais do que
isso, ocorre um estouro de pilha (stack overflow) que geralmente termina o
programa imediatamente. Já o heap pode crescer através de chamadas de sistema
como brk ou mmap, solicitando mais páginas de memória ao sistema
operacional. Essa flexibilidade permite alocar grandes quantidades de memória,
mas com o custo de maior overhead e a responsabilidade de gerenciamento manual.
O que isso significa para você? Significa que você precisa entender que algumas vezes você (programador, portanto dono do processo de um programa) vai precisar se preocupar em pedir memória para o sistema. Vamos entender isso melhor?
Stack vs heap e alocação dinâmica
Section titled “Stack vs heap e alocação dinâmica”A pilha é uma região de memória gerenciada automaticamente pelo compilador. Quando você declara uma variável local dentro de uma função, ela é alocada na pilha. A alocação é extremamente rápida, envolvendo apenas o deslocamento de um ponteiro de pilha. Quando a função termina, todas as variáveis locais são automaticamente desalocadas. A vida útil dos objetos na pilha está estritamente ligada ao escopo em que foram criados.
O heap, por outro lado, é uma região de memória gerenciada manualmente pelo
programador. Quando você precisa de memória que deve persistir além do
escopo de uma função, ou quando o tamanho necessário só é conhecido em
tempo de execução, você aloca no heap usando operadores como new.
Esta memória permanece alocada até que você explicitamente a libere com
delete, ou até que o programa termine.
A diferença de desempenho entre stack e heap é significativa. A pilha oferece alocação e desalocação praticamente instantâneas, enquanto o heap requer chamadas ao sistema operacional e gerenciamento de estruturas de dados complexas. Além disso, a memória da pilha geralmente já está no cache da CPU devido à sua natureza sequencial e previsível.
Então por que não usamos apenas a pilha? A limitação fundamental é que o tamanho da pilha é fixo e relativamente pequeno, tipicamente alguns megabytes. Alocar objetos muito grandes na pilha pode causar estouro de pilha (stack overflow). Além disso, a pilha não permite que objetos sobrevivam ao escopo onde foram criados, o que é necessário em muitos padrões de programação.
O alocador de memória padrão do C++ (geralmente implementado usando
malloc/free por baixo) gerencia um pool de memória obtida do sistema.
Quando você chama new, o alocador tenta encontrar um bloco livre
dentro deste pool. Se não houver memória suficiente, ele pede mais ao
sistema operacional. Quando você chama delete, a memória é devolvida ao
pool, mas não necessariamente ao sistema operacional imediatamente.
Quando você usa o alocador, dizemos que está trabalhando com alocação dinâmica. Sempre que isso acontece, o resultado do processo de alocação é o endereço de um espaço de memória. Em outras palavras, um ponteiro.
Ponteiros clássicos
Section titled “Ponteiros clássicos”Ponteiros crus oferecem controle total sobre a memória, mas este poder vem com responsabilidade. Erros com ponteiros são uma das principais fontes de bugs em C++.
#include <iostream>
int main() { int* p = new int(42); std::cout << *p << "\n"; delete p; // obrigatório}Quando trabalhamos com arrays alocados dinamicamente, devemos usar delete[]
em vez de delete simples:
int* arr = new int[10];arr[0] = 7;delete[] arr; // não use delete simples aquiA diferença é crucial: delete simples chama o destrutor apenas do primeiro
elemento, enquanto delete[] chama o destrutor de cada elemento do array.
Usar o operador errado resulta em comportamento indefinido.
Os erros mais comuns com ponteiros crus incluem confundir delete com
delete[], chamar delete duas vezes no mesmo ponteiro (double free),
usar um ponteiro após liberar a memória (dangling pointer), e retornos
precoces ou exceções que fazem o programa pular a chamada de delete.
O que acontece quando um programa pula a chamada do delete?
Vazamento de memória
Section titled “Vazamento de memória”Faça um experimento agora:
- Abra o gerenciador de tarefas e veja quanto de memória o seu sistema está atualmente utilizando. Anote esse valor;
- Abra o Chrome e note a variação de uso de memória. Pode abrir umas duas abas e ver o quanto isso faz o uso de memória variar;
- Feche o Chrome e cheque novamente o uso de memória.
A pergunta fundamental é: a quantidade de memória utilizada pelo sistema voltou ao valor anterior, observado em 1? Não? Então você acabou de ver um vazamento de memória.
Um vazamento de memória ocorre quando alocamos memória no heap mas esquecemos de liberá-la. Considere este exemplo problemático:
#include <iostream>
struct Foo { int x{42}; };
void f(bool fail) { Foo* p = new Foo(); if (fail) return; // vazou - delete nunca é chamado std::cout << p->x << "\n"; delete p;}
int main() { f(true); }Se a função retornar prematuramente devido a fail ser true, a memória
alocada nunca é liberada. Em um programa real, vazamentos como este
acumulados ao longo do tempo podem esgotar a memória disponível.
Claro que você conseguiria detectar um erro tão elementar em alguns segundos, certo? Certo, mas talvez esse erro passe batido em um projeto com milhões de linhas de código. Esse é o caso do Chrome (mais de 30 milhões de LoC). Aí fica complicado, né?
É por isso que existem ferramentas para te ajudar a detectar vazamento de
memória. Uma delas é o valgrind. Para usá-la, execute:
g++ -std=c++17 -O0 -g leak.cpp -o leakvalgrind --leak-check=full ./leakO relatório do Valgrind indicará algo como definitely lost: 16 bytes in 1 blocks, confirmando que há memória alocada que não foi liberada.
A solução elegante é usar std::unique_ptr, que gerencia automaticamente
a vida do objeto:
#include <iostream>#include <memory>
struct Foo { int x{42}; };
void f(bool fail) { auto p = std::make_unique<Foo>(); if (fail) return; // objeto é destruído automaticamente std::cout << p->x << "\n";}
int main() { f(true); }Com std::unique_ptr, não precisamos nos preocupar com caminhos de retorno
ou exceções. O objeto é sempre destruído quando o ponteiro sai de escopo.
Esse é um bom momento para que você, programador de Python ou amante de Node, faça a afirmação que deve estar na ponta da sua língua:
Eu nunca precisei me preocupar com isso enquanto trabalhava! Tá vendo? É por isso que ninguém quer programar em C++.
— Typescripto da silva
O motivo disso é que essas linguagens usam garbage collector
Um garbage collector é um mecanismo automático de gerenciamento de memória presente em linguagens como Java, Python, Go e C#. Em vez do programador chamar explicitamente funções para liberar memória, o GC monitora periodicamente quais objetos ainda estão sendo referenciados e quais podem ser liberados. Isso elimina uma classe inteira de bugs como vazamentos de memória e double free, tornando o desenvolvimento mais seguro e produtivo.
O custo dessa conveniência é o impacto na performance. O GC precisa periodicamente pausar a execução do programa para analisar todas as referências de memória e limpar objetos não utilizados. Essas pausas, chamadas de “stop-the-world”, podem causar latências imprevisíveis, especialmente em aplicações que exigem resposta em tempo real. Além disso, o overhead contínuo de rastreamento de referências consome ciclos de CPU que poderiam ser usados pela aplicação.
Cada abordagem tem seu lugar. Linguagens com garbage collector são excelentes para desenvolvimento web, aplicações empresariais e prototipagem rápida, onde a produtividade do desenvolvedor e a segurança da memória são prioritárias. Linguagens de sistema como C++ são essenciais para sistemas operacionais, drivers, jogos, sistemas embarcados e aplicações de alta performance, onde o controle determinístico sobre a memória e a ausência de pausas imprevisíveis são críticos. O ecossistema de software moderno precisa de ambos os tipos de linguagem trabalhando em conjunto.
Legal, mas então isso significa que o programador de linguagens de sistema está fadado a sofrer com os próprios erros de gerenciamento de memória, certo?
Errado. É aí que entra o conceito de RAII.
Trabalhar com ponteiros crus oferece controle total, mas exige disciplina
rigorosa. Cada new precisa de um new[] ou delete correspondente,
cada new[] precisa de um delete[], e você deve garantir que nenhum
caminho de execução escape dessas liberações. Em código complexo com múltiplos
retornos, exceções e caminhos condicionais, isso se torna rapidamente
impraticável e propenso a erros.
A boa notícia é que C++ moderno oferece uma solução elegante. Em vez de gerenciar memória manualmente, podemos usar objetos que encapsulam ponteiros e gerenciam automaticamente sua vida útil. Quando esses objetos saem de escopo, eles liberam a memória automaticamente, garantindo que nenhum vazamento ocorra, independentemente de como a função termine. Essa abordagem, conhecida como RAII (Resource Acquisition Is Initialization), é o padrão moderno de gerenciamento de memória em C++.
Ponteiros inteligentes
Section titled “Ponteiros inteligentes”A biblioteca <memory> oferece três tipos de smart pointers que gerenciam
automaticamente a vida dos objetos. Eles eliminam a necessidade de chamadas
explícitas a delete e previnem os erros mais comuns de gerenciamento de
memória.
unique_ptr
Section titled “unique_ptr”O std::unique_ptr representa propriedade exclusiva sobre um objeto. Ele
é leve, não adiciona overhead em comparação com ponteiros crus, e não pode
ser copiado, apenas movido. Quando o unique_ptr sai de escopo, o objeto
apontado é automaticamente destruído.
Sempre que possível, crie unique_ptr usando std::make_unique em vez de
chamar new diretamente. Isso é mais seguro e eficiente:
#include <memory>#include <iostream>
int main() { auto p = std::make_unique<int>(42); std::cout << *p << "\n"; auto q = std::move(p); // transfere propriedade; p vira nullptr}A semântica de movimento é fundamental aqui. Quando transferimos um unique_ptr para outra variável ou função, a propriedade é movida, não copiada. O ponteiro original fica vazio (nullptr) após a operação.
Para transferir propriedade para uma função:
#include <memory>#include <iostream>
void consume(std::unique_ptr<int> p) { std::cout << *p << "\n";}
int main() { auto p = std::make_unique<int>(42); consume(std::move(p)); // p fica vazio após a chamada}Para arrays alocados dinamicamente, o unique_ptr possui uma
especialização que gerencia a memória corretamente, chamando delete[]
automaticamente:
#include <memory>
int main() { std::unique_ptr<int[]> arr(new int[10]); arr[0] = 7; // delete[] é chamado automaticamente ao sair do escopo}Use unique_ptr como padrão sempre que precisar de propriedade única de um objeto no heap. Ele é eficiente, seguro e torna explícito que há apenas um dono do recurso.
shared_ptr
Section titled “shared_ptr”O std::shared_ptr implementa propriedade compartilhada através de
contagem de referências. Cada cópia do shared_ptr incrementa um contador
atômico, e cada destruição decrementa. Quando o contador chega a zero, o
objeto é destruído automaticamente.
#include <memory>#include <iostream>
int main() { auto sp1 = std::make_shared<std::string>("oi"); auto sp2 = sp1; // contagem incrementada para 2 std::cout << sp1.use_count() << "\n"; // imprime 2 // Quando sp1 e sp2 saírem de escopo, o objeto será destruído}Shared pointers têm overhead significativo devido à contagem de referências thread-safe. Use apenas quando a vida do objeto realmente precisa ser compartilhada entre múltiplos proprietários que não têm uma relação clara de pai-filho.
Um problema sério com shared_ptr é a possibilidade de ciclos de referência. Quando dois objetos se referenciam mutuamente via shared_ptr, cada um mantém o outro vivo, impedindo que ambos sejam destruídos mesmo quando nenhum código externo os referencia mais:
#include <memory>#include <iostream>
struct B;struct A { std::shared_ptr<B> b; ~A() { std::cout << "A destruído\n"; }};struct B { std::shared_ptr<A> a; ~B() { std::cout << "B destruído\n"; }};
int main() { auto a = std::make_shared<A>(); auto b = std::make_shared<B>(); a->b = b; b->a = a; // ciclo criado // Nenhum destrutor será chamado - vazamento de memória!}weak_ptr
Section titled “weak_ptr”Para resolver o problema de ciclos em shared_ptr, usamos std::weak_ptr,
que funciona como um observador que não mantém o objeto vivo. Um weak_ptr
não incrementa o contador de referências, permitindo que o objeto seja
destruído normalmente.
#include <memory>#include <iostream>
struct B;struct A { std::weak_ptr<B> b; // weak em vez de shared ~A() { std::cout << "A destruído\n"; }};struct B { std::shared_ptr<A> a; ~B() { std::cout << "B destruído\n"; }};
int main() { auto a = std::make_shared<A>(); auto b = std::make_shared<B>(); a->b = b; b->a = a; // agora sem ciclo forte // Ambos serão destruídos corretamente
// Para usar o weak_ptr, precisamos converter para shared_ptr if (auto locked = a->b.lock()) { std::cout << "B ainda existe, pode usar\n"; } else { std::cout << "B já foi destruído\n"; }}O método lock() tenta converter o weak_ptr em um shared_ptr. Se o
objeto ainda existir, retorna um shared_ptr válido e incrementa o contador
temporariamente. Se o objeto já foi destruído, retorna nullptr. Sempre
verifique o resultado de lock() antes de usar.
Use weak_ptr quando precisar observar um objeto gerenciado por shared_ptr sem afetar sua vida útil, ou quando precisar quebrar ciclos de referência em estruturas de dados complexas.
Dicas e comandos úteis
Section titled “Dicas e comandos úteis”Ao trabalhar com gerenciamento de memória em C++, siga estas diretrizes práticas.
Preferência por containers e objetos locais:
Sempre que possível, use containers da biblioteca padrão como
std::vector e std::string, ou simplesmente objetos locais na pilha.
Estas opções são seguras, eficientes e eliminam preocupações com
gerenciamento manual.
Ponteiros crus com cautela:
Ponteiros crus e referências ainda têm seu lugar, mas devem ser usados
apenas para acesso temporário sem assumir propriedade. Nunca chame delete
manualmente em um ponteiro cru quando alternativas modernas estão
disponíveis.
Compilação com símbolos de debug: Para compilar exemplos com informações de debug, útil para ferramentas como Valgrind:
g++ -std=c++17 -O0 -g arquivo.cpp -o execDetecção de vazamentos com Valgrind: Para verificar se seu programa tem vazamentos de memória:
valgrind --leak-check=full ./execO relatório indicará vazamentos com mensagens como definitely lost ou
possibly lost, apontando exatamente onde a memória foi alocada e não
liberada.